
古老的 Intel8086 处理器
8086 是 Intel 公司的第一款 16 位处理器,诞生于 1978 年,应该比各位小伙伴的年龄都大一些。
在 Intel 公司的所有处理器中,它占有很重要的地位,是整个 Intel 32 位架构处理器(IA-32)的开山鼻祖。
那么,问题来了,什么叫 16 位的处理器?
有些人会把处理器的位数与地址总线的位数搞混在一起!
我们知道,CPU 在访问内存的时候,是通过地址总线来传送物理地址的。
8086 CPU 有 20 位的地址线,可以传送 20 位地址。
每一根地址线都表示一个 bit,那么 20 个 bit 可以表示的最大值就是 2 的 20 次方。
也就是说:最大可以定位到 1M 地址的内存,这称作 CPU 的寻址能力。
但是,8086 处理器却是 16 位的,因为:
运算器一次最多可以处理 16 位的数据;
寄存器的最大宽度为 16 位;
寄存器和运算器之间的通路为 16 位;
也就是说:在 8086 处理器的内部,能够一次性处理、传输、暂时存储的最大长度是 16 位,因此,我们说它是 16 位结构的 CPU。
主存储器是什么?
计算机的本质就是对数据的存储和处理,那么参与计算的数据是从哪里来的呢?那就是一个称作 存储器(Storage 或 Memory)的物理器件。
从广义上来说,只要能存储数据的器件都可以称作存储器,比如:硬盘、U盘等。
但是,在计算机内部,有一种专门与 CPU 相连接,用来存储正在执行的程序和数据的存储器,一般称作内存储器或者主存储器,简称:内存或主存。
内存按照字节来组织,单次访问的最小单位是 1 个字节,这是最基本的存储单元。
每一个存储单元,也就是一个字节,都对应着一个地址,如下图所示:
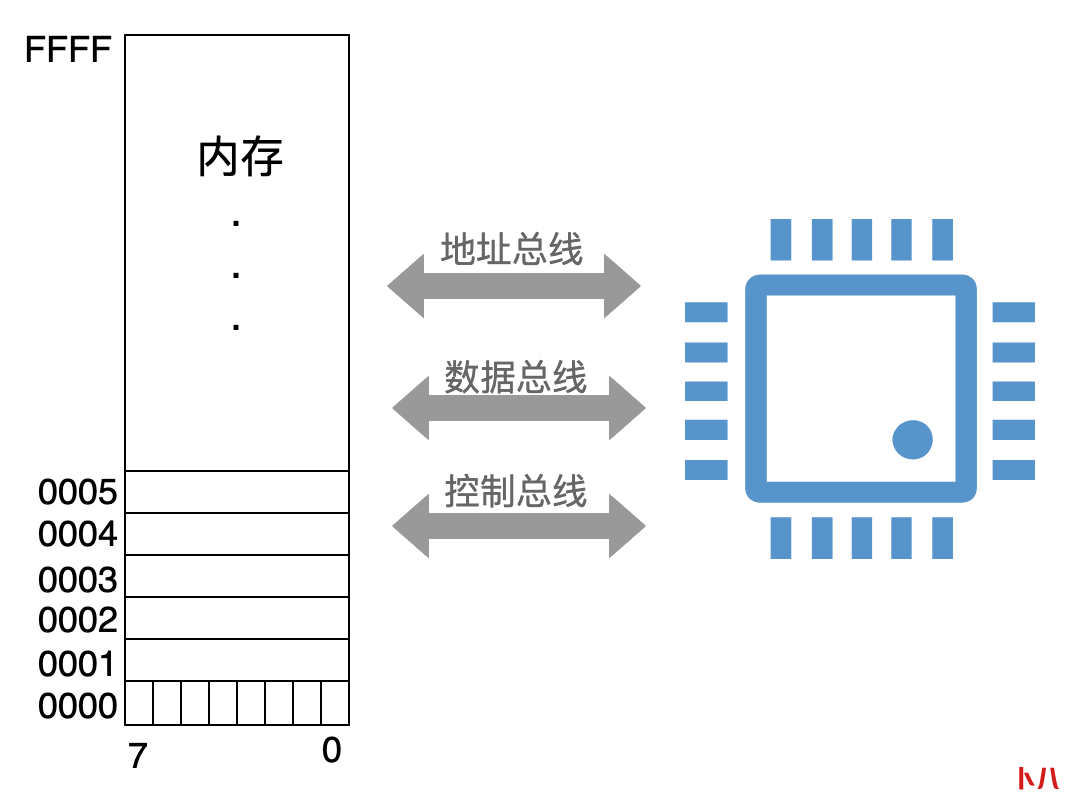
CPU 就通过地址总线来确定:对内存中的哪一个存储单元中的数据进行访问。
第 1 个字节的地址是 0000H,第 2 个字节的地址是 0001H,后面以此类推。
图中的这个内存,最大存储单元的地址是 FFFFH,换算成十进制就是 65535,因此这个内存的容量是 65536 字节,也就是 64 KB。
这里有一个原子操作的问题可以考虑一下。
在 Linux 内核代码中,很多地方使用了原子操作,比如:互斥锁的实现代码。
为什么原子操作需要对变量的类型限制为 int 型呢?这就涉及到对内存的读写操作了。
尽管内存的最小组成单位是字节,但是,经过精心的设计和安排,不同位数的 CPU,能够按照字节、字、双字进行访问。
换句话说,仅通过单次访问,16 位处理器就能处理 16 位的二进制数,32 位处理器就能处理 32 位的二进制数。
寄存器是什么?
在 CPU 内部,一些都是代表 0 或 1 的电信号,这些二进制数字的一组电信号出现在处理器内部线路上,它们是一排高低电平的组合,代表着二进制数中的每一位。
在处理器内部,必须用一个称为寄存器的电路把这些数据锁存起来。
因此,寄存器本质上也属于存储器的一种。只不过它们位于处理器的内部,CPU 访问寄存器比访问内存的速度更快。
处理器总是很忙的,在它操作的过程中,所有数据在寄存器里面只能是临时存在一小会,然后再被送往别处,这就是为什么它被叫做“寄存器”。
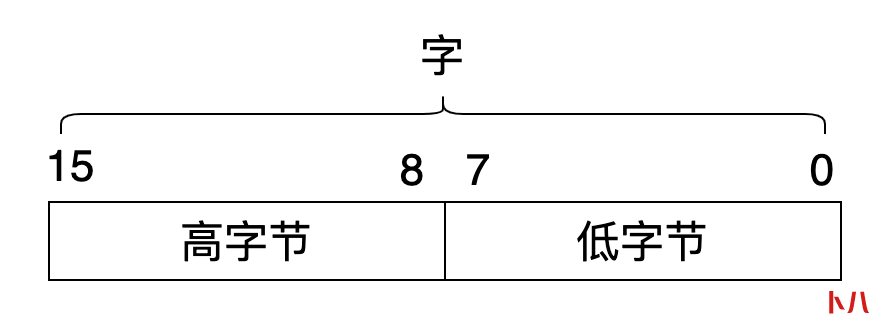
8086 中的寄存器都是 16 位的,可以存放 2 个字节,或者说 1 个字。高字节在前(bit8 ~ bit15),低字节在后(bit0 ~ bit7)。
8086 中有下面这些寄存器:
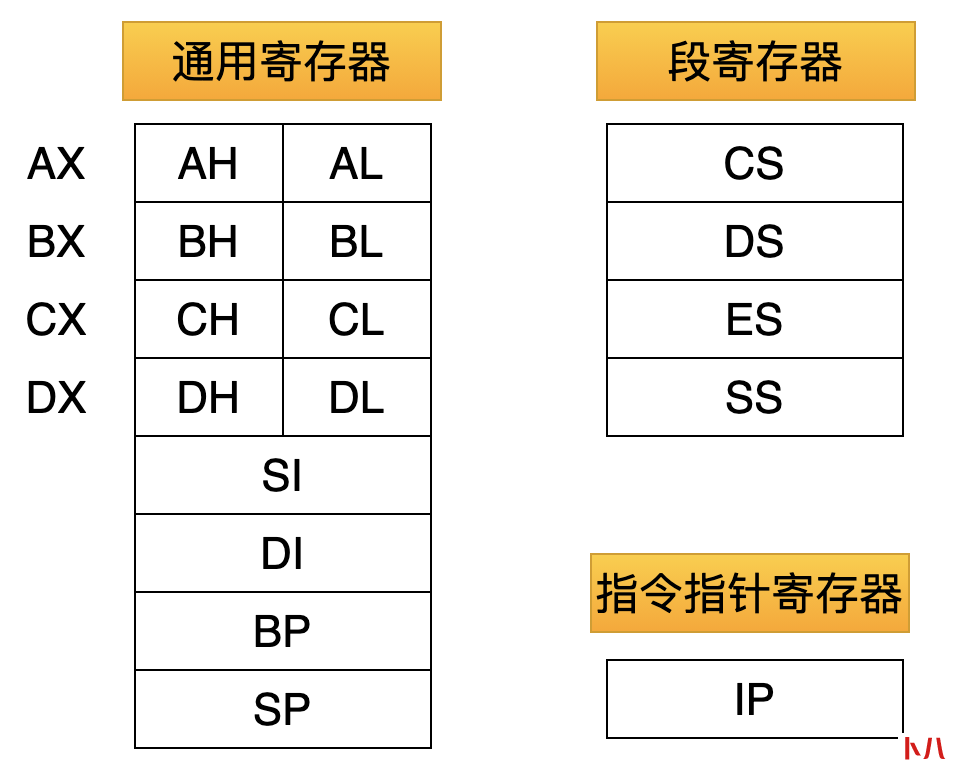
刚才说了,这些寄存器都是 16 位的。由于需要与以前更古老的处理器兼容,其中的 4 个寄存器:AX、BX、CX、DX 还可以当成 2 个 8 位的寄存器来使用。
比如:AX 代表一个 16 位的寄存器,AH、AL 分别代表一个 8 位的寄存器。
mov AX, 5D 表示把 005D 送入 AX 寄存器(16 位)
mov AL, 5D 表示把 5D 送入 AL 寄存器(8 位)
三个总线
当我们启动一个应用程序的时候,这个程序的代码和数据都被加载到物理内存中。
CPU 无论是读取指令,还是操作数据,都需要与内存进行信息的交互:
确定存储单元的地址(地址信息);
器件的选择,读或写的命令(控制信息);
读或写的数据(数据信息);
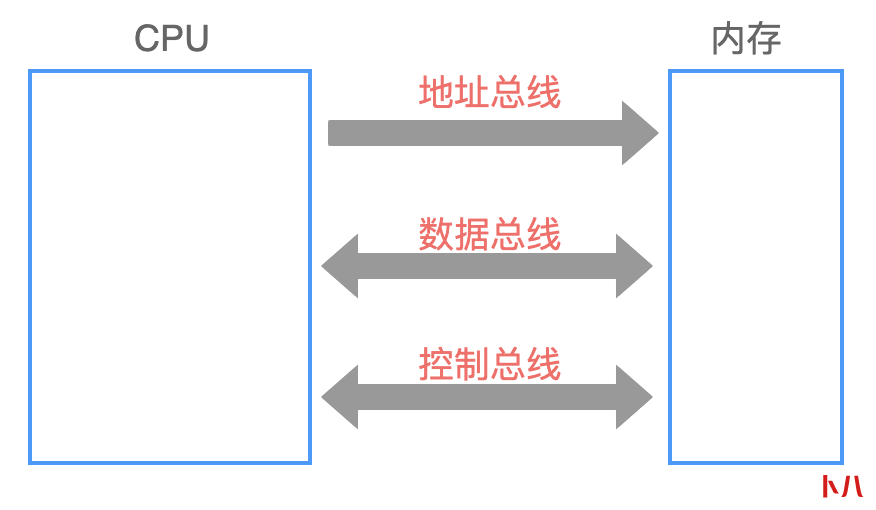
在计算机中,有专门连接 CPU 和其他芯片的数据,称为总线。
从逻辑上来分类,包括下面 3 种总线:
地址总线:用来确定存储单元的地址;
控制总线: CPU 对外部器件进行控制;
数据总线: CPU 与内存或其他器件之间传送数据;
8086 有 20 根地址线,称作地址总线的宽度,它可以寻址 2 的 20 次方个内存单元。
同样的道理,8086 数据总线的宽度是 16,也就是一次性可以传送 16 bit 的数据。
控制总线决定了 CPU 可以对外进行多少种控制,决定了 CPU 对外部器件的控制能力。
CPU 如何对内存进行寻址?
在 Linux 2.6 内核代码中,编译器产生的地址叫做虚拟地址(也称作:逻辑地址),这个逻辑地址经过段转换之后,变成线性地址,线性地址再经过分页转换,就得到最终物理内存上的物理地址。
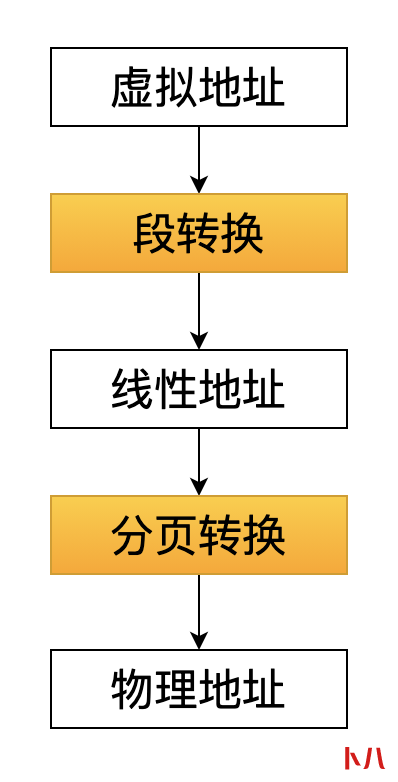
还记得文章开头的那张段描述符的表格吗?
其中的代码段和数据段描述符的起始地址都是 0x00000000,也就是说: 在数值上虚拟地址和转换后的线性地址是相等的(稍后就会明白为什么是这样)。
我们再来看看一下 8086 中更简单的地址转换。
刚才说到,内存是一个线性的存储器件,CPU 依赖地址来定位每一个存储单元。
对于 8086 CPU 来说,它有 20 根地址线,可以传送 20 位地址,达到 1MB 的寻址能力。
但是 8086 又是 16 位的结构,在内部一次性处理、传输、暂时存储的地址只有 16 位。
从内部结构来看,如果将地址从内部简单的发出到地址总线上,只能送出 16 位的地址,这样的话,寻址能力只有 64KB。
那么应该怎么才能充分利用 20 根地址线呢?
8086 CPU 采用: 在内部使用两个 16 位地址合成的方法,来形成一个 20 位的物理地址,如下所示:
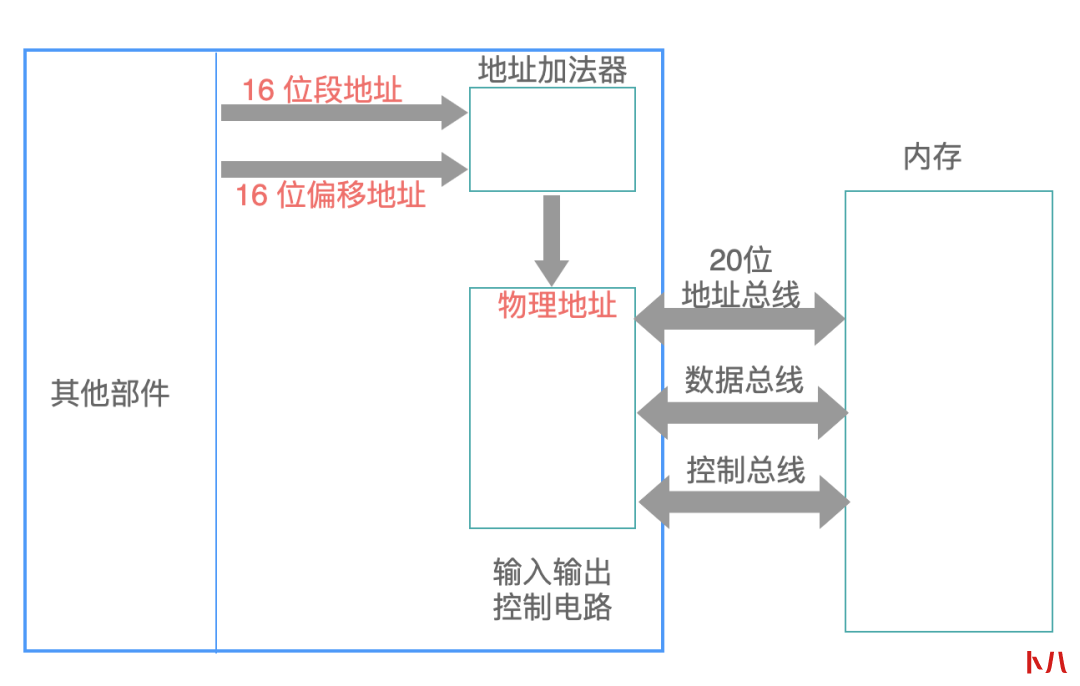
第一个 16 位的地址称为段地址,第二个 16 位的地址称为偏移地址。
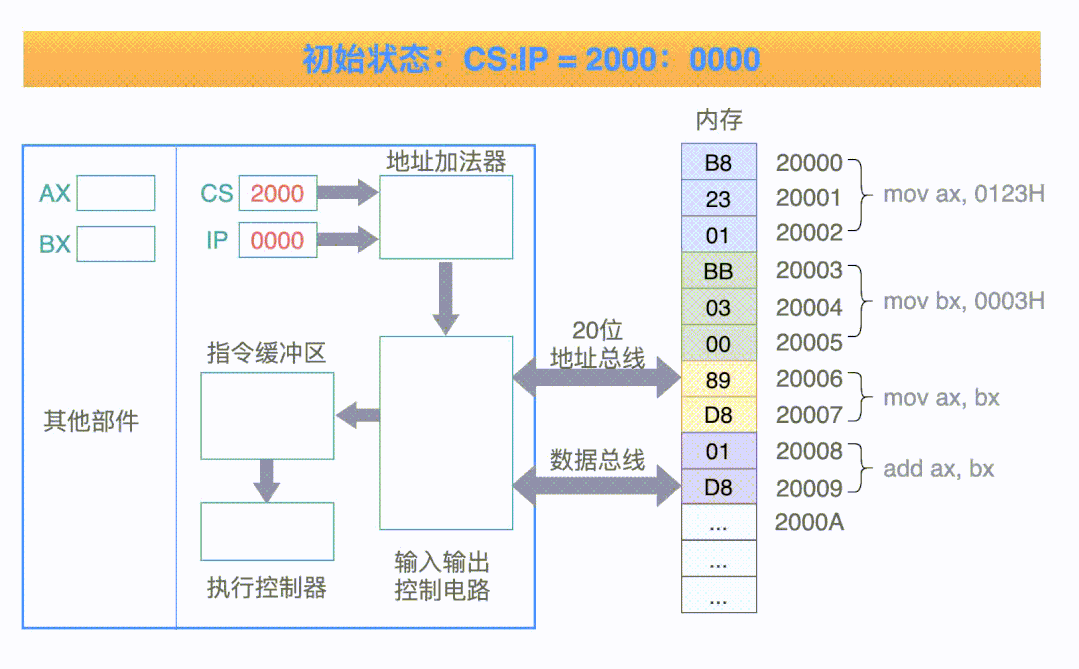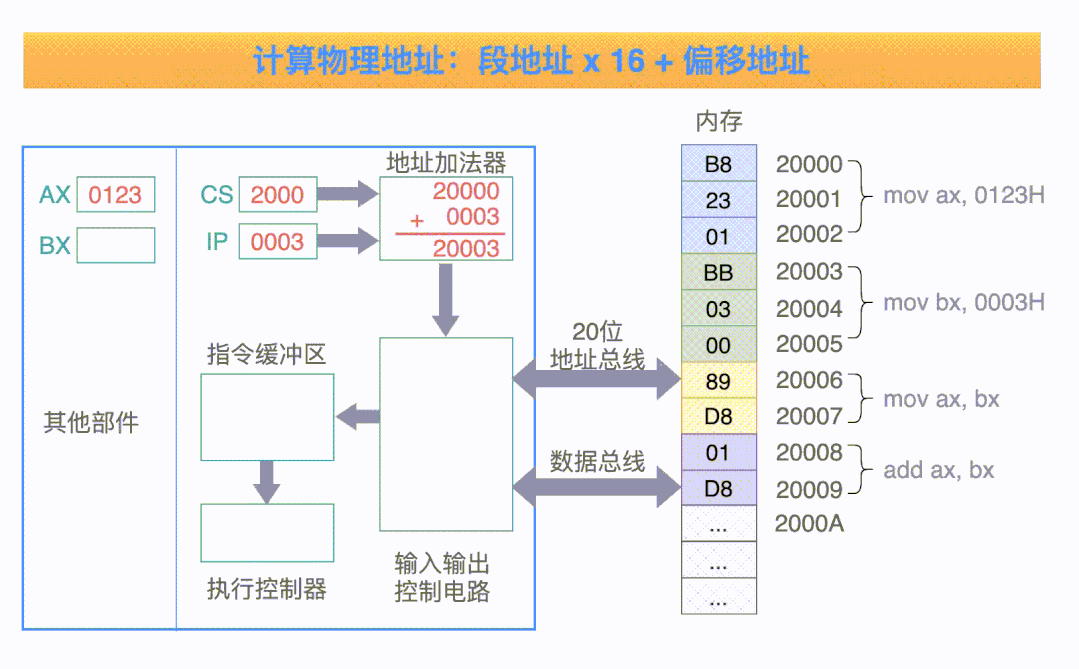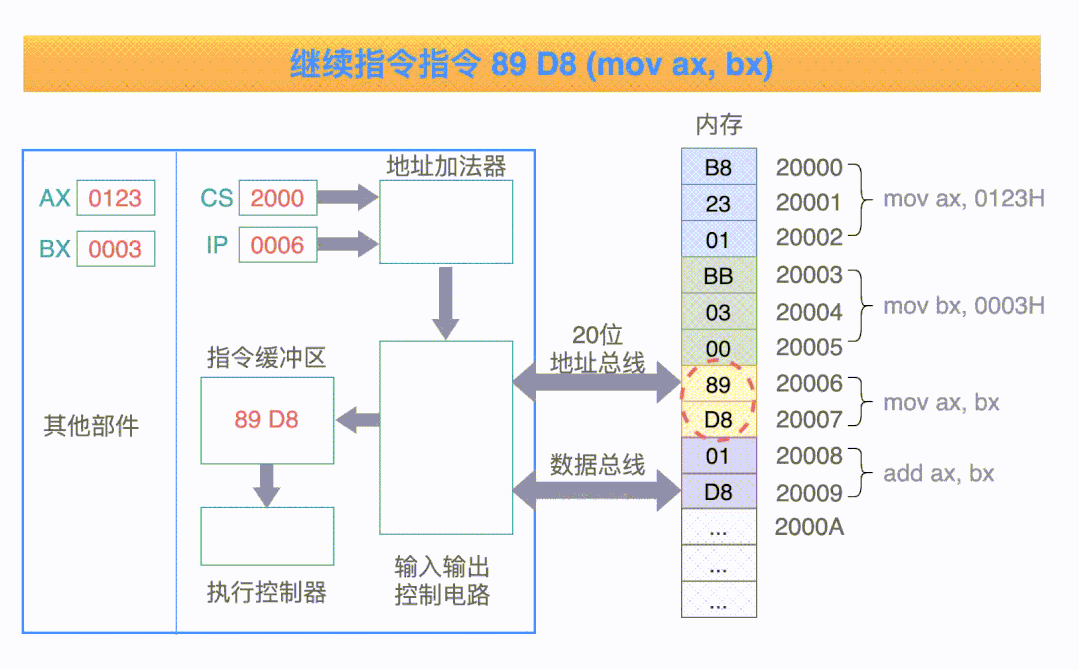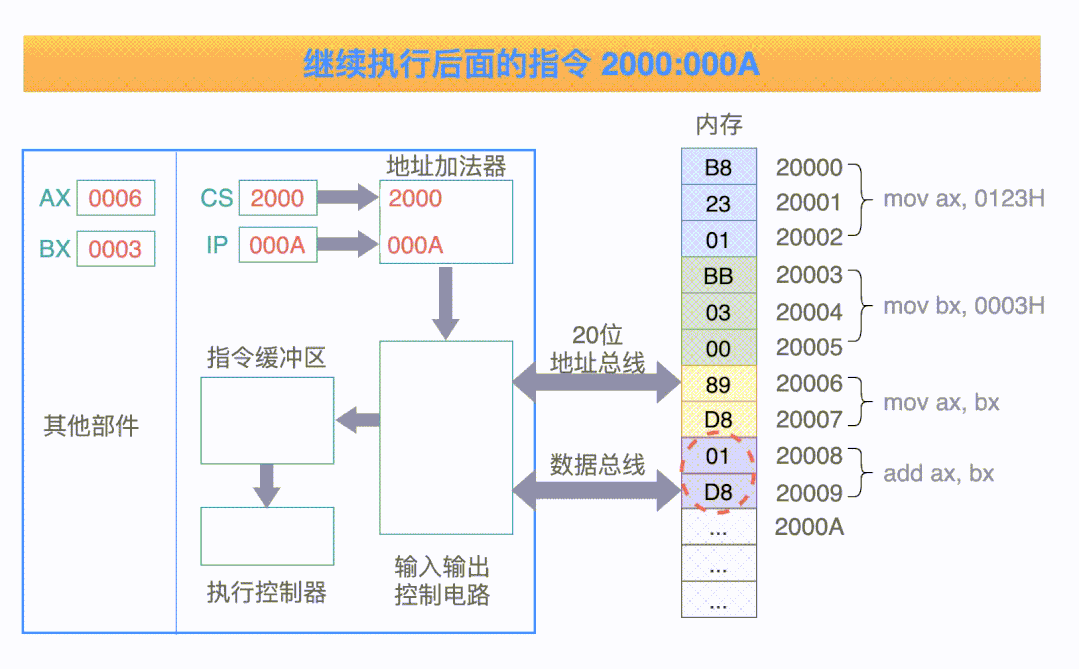
地址加法器采用下面的这个公式,来“合成”得到一个 20 位的物理地址:
物理地址 = 段地址 x 16 + 偏移地址
例如:我们编写的程序,在加载到内存中之后,放在一个内存空间中。
CPU 在执行这些指令的时候,把 CS 寄存器当做段寄存器,把 IP 寄存器当做偏移寄存器,然后计算 CS x 16 + IP 的值,就得到了指令的物理地址。
从以上的描述中可以看出:8086 CPU 似乎是因为寄存器无法直接输出 20 位的物理地址,不得已才使用这样的地址合成方式。
其实更本质的原因是:8086 CPU 就是想通过 基地址 + 偏移量 的方式来对内存进行寻址(这里的基地址,就是段地址左移 4 位)。
也就是说,即使 CPU 有能力直接输出一个 20 位的地址,它仍然可能会采用 基地址 + 偏移量的方式来进行内存寻址。
想一下:我们在 Linux 系统中编译一个库文件的时候,一般都会在编译选项中添加 -fPIC 选项,表示编译出来的动态库是地址无关的,在被加载到内存时需要被重定位。
而基地址+偏移量的寻址模式,就为重定位提供了底层支撑。
我们是如何控制 CPU 的?
CPU 其实是一个很纯粹、很呆板的一个东西,它唯一做的事情就是:到 CS:IP 这两个寄存器指定的内存单元中取出一条指令,然后执行这条指令:
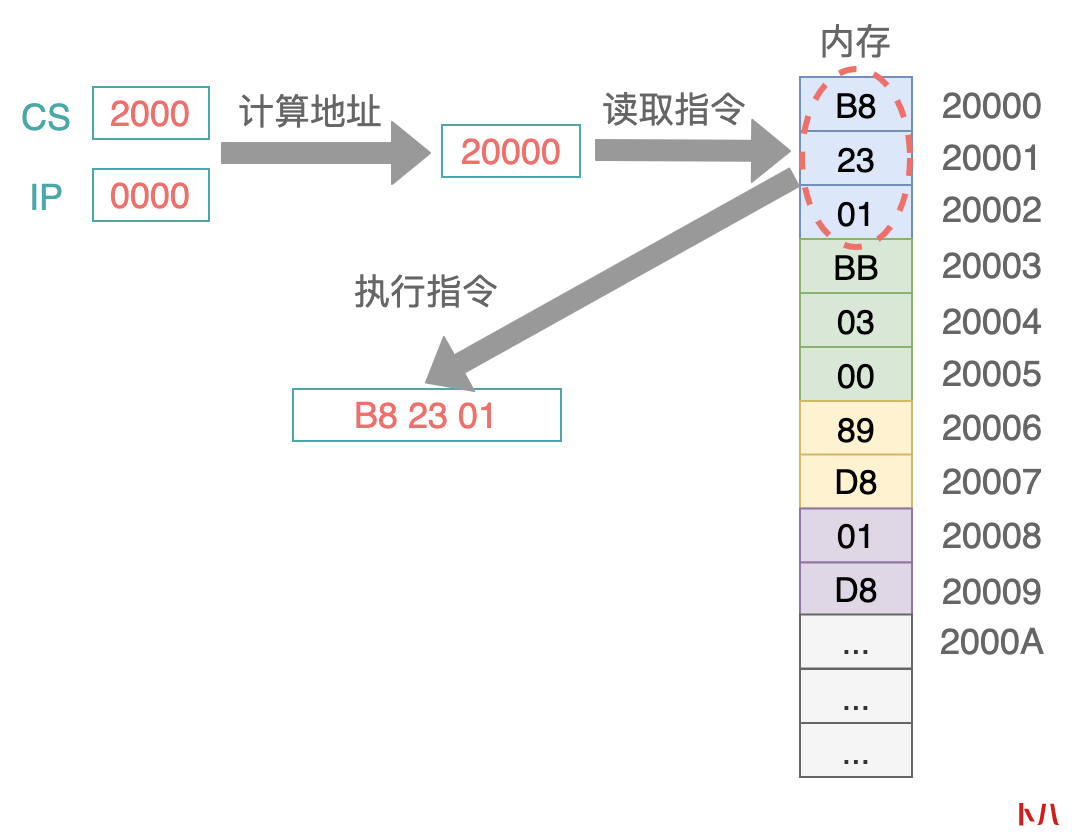
当然了,还需要预先定义一套指令集,在内存中的指令区中,存储的都必须是合法的指令,否则 CPU 就不认识了。
每一条指令都是用某些特定的数(指令码)来指示 CPU 进行特定的操作。
CPU 认识这些指令,一看到这些指令码,CPU 就知道这个指令码后面还有几个字节的操作数、需要进行什么样的操作。
例如:指令码 F4H 表示让处理器停机,当 CPU 执行这条指令的时候,就停止工作。
(其实这里说 CPU 已经有点不准确了,因为 CPU 是囊括了很多器件的一个整体,也许这里说 CPU 中的执行单元会更准确些。)
另外有一点可以提前说一下:内存中的一切都是数据,至于把其中的哪一部分数据当做指令来执行,哪一部分数据当做被指令操作的“变量”,这完全是由操作系统的设计者来规划的。
在 8086 处理器的层面来说,只要是 CS:IP “指向”的内存区域,都被当做指令来执行。
从以上描述可以看出:在 CPU 中,程序员能够用指令读写的器件只有寄存器,我们可以通过改变寄存器中的内容,来实现对 CPU 的控制。
更直白的说就是:我们可以通过改变 CS、IP 寄存器中的内容,来控制 CPU 执行目标指令。
作为一名合格的嵌入式开发者,大家估计都配置过一些单片机里的寄存器,以达到一些功能定义、端口复用的目的,其实这些操作,都可以看做是我们对 CPU 的控制。
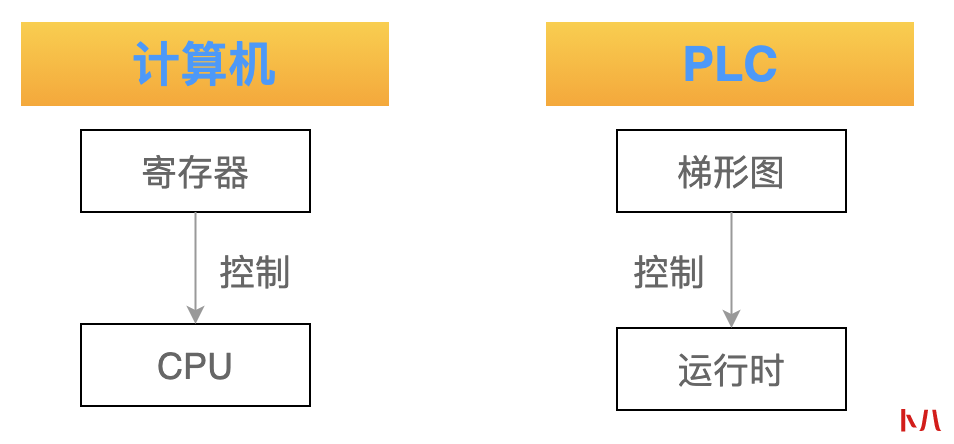
如果把 CPU 比作木偶,那么 寄存器就是控制木偶的绳索。
我们再把 CPU 与 工控领域的 PLC 编程进行类比一下。
我们在拿到一个新的 PLC 设备之后,其中只有一个运行时(runtime),这个运行时执行的本职工作就是:
扫描所有的输入端口,锁存在输入映象区;
执行一个运算、控制逻辑,得到一些列输出信号,锁存到输出映象区;
把输出映象区的信号,刷新到输出端口;
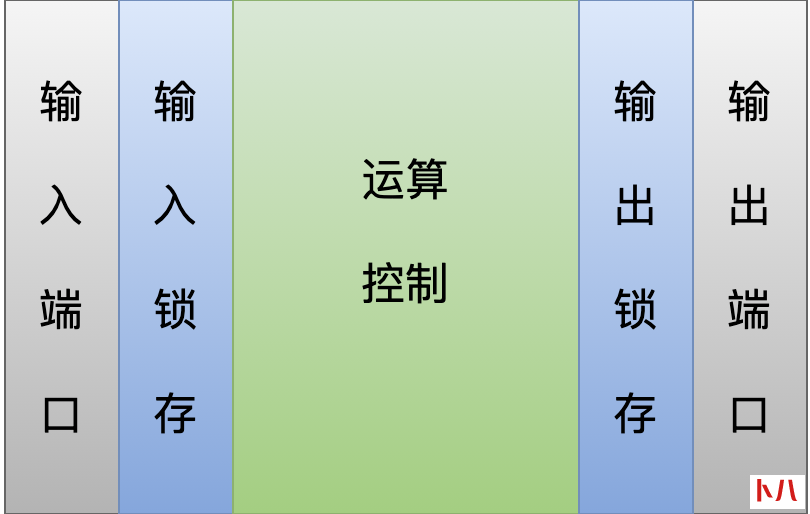
在一个全新的 PLC 中,其中第 2 个步骤中需要的运算、控制逻辑可能就不存在。
因此,单单一个 runtime,PLC 是无法完成一件有意义的工作的。
为了让 PLC 完成一个具体的控制目标,我们还需要利用 PLC 厂家提供的上位机编程软件,开发一个运算、控制逻辑程序,编程语言一般都是梯形图居多。
当这个程序被下载到 PLC 中之后,它就可以控制运行时来做一些有意义的工作了。
我们可以简单的认为:梯形图就是用来控制 PLC 的运行时。
对于 CPU 来说,想让它执行某个内存单元的指令,只要修改寄存器 CS 和 IP 即可。
换句话说:只要对一个程序的内存布局足够的清楚,可以把 CPU 玩弄于股掌之间,让它执行哪里的代码都可以。
CPU 执行指令流程
现在我们已经明白了地址转换、内存的寻址,距离 CPU 执行一条指令需要的最小单元还剩下:指令缓冲区和控制电路。
简单来说:指令缓冲区用来缓存从内存中读取的指令,控制电路用来协调各种器件对总线等资源的使用。
对于下面这张图来说,它一共有 4 条指令:
以第一条指令来举例,它一共经过 5 个步骤:
把 CS:IP 内容送入地址加法器,计算得到 20 位的物理地址 20000H;
控制电路把 20 位的地址,送入到地址总线;
内存中 20000H 单元处的指令 B8 23 01,经过数据总线被送到指令缓冲区;
指令偏移寄存器 IP 的值要加 3,指向下一条等待被执行的偏移地址(因为指令码 B8 代表当前指令的长度是 3 个字节);
执行指令缓冲区中的指令: 把数值 0123H 送入寄存器 AX 中;
以上就是一条指令的执行最基本步骤,当然,现代处理器的指令执行流程,比这里的要复杂的多得多。


 cpu温度过高导致自动关机怎么解决...
cpu温度过高导致自动关机怎么解决...  CPU过热故障分析...
CPU过热故障分析...  很多用户在选择电脑时候会看见6核处理器以及8核处理器,很多用户不知道该如何选择,也对两者的区别不是特别了解...
很多用户在选择电脑时候会看见6核处理器以及8核处理器,很多用户不知道该如何选择,也对两者的区别不是特别了解...  很多DIYer都走入了一个误区:CPU一定要选性能最好的,性价比最高的,而且不仅要兼顾游戏还要驾驭多任务工作。然而很大一部分消费者买电脑更多只是为了玩游戏,甚至说只是玩一些...
很多DIYer都走入了一个误区:CPU一定要选性能最好的,性价比最高的,而且不仅要兼顾游戏还要驾驭多任务工作。然而很大一部分消费者买电脑更多只是为了玩游戏,甚至说只是玩一些...  这里有着2021最新的高通骁龙处理器性能排行榜哦,让用户们可以更好的进行查看哦。用户们还可以在这里不断的查看...
这里有着2021最新的高通骁龙处理器性能排行榜哦,让用户们可以更好的进行查看哦。用户们还可以在这里不断的查看...  现在市面上的电脑处理器类型有很多,很多小伙伴在选择处理器的时候都无从下手。这不,最近就有小伙伴纠结于锐...
现在市面上的电脑处理器类型有很多,很多小伙伴在选择处理器的时候都无从下手。这不,最近就有小伙伴纠结于锐...  很多刚接触硬件的玩家对于参数的概念可能是模棱两可的,又或者是记得不那么清晰的,笔者就记得曾经去商场里购买笔记本电脑的时候,被导购那一顿忽悠啊,说什么i5处理器性能强...
很多刚接触硬件的玩家对于参数的概念可能是模棱两可的,又或者是记得不那么清晰的,笔者就记得曾经去商场里购买笔记本电脑的时候,被导购那一顿忽悠啊,说什么i5处理器性能强...  B150主板搭配什么CPU更好用...
B150主板搭配什么CPU更好用...  今年DIY市场最引人瞩目的明星产品,就是三代锐龙了,它之所以这么受人期待,终究是因为天下苦牙膏久矣。Intel在发布酷睿统治了CPU市场后,最高四核8线程,基本年换主板,14nm用1万...
今年DIY市场最引人瞩目的明星产品,就是三代锐龙了,它之所以这么受人期待,终究是因为天下苦牙膏久矣。Intel在发布酷睿统治了CPU市场后,最高四核8线程,基本年换主板,14nm用1万...  卡扣cpu风扇怎么拆...
卡扣cpu风扇怎么拆...  笔记本电脑cpu坏了怎么办...
笔记本电脑cpu坏了怎么办...  CPU是一台电脑最关键的核心硬件之一,它的性能好坏,直接影响了电脑的运行...
CPU是一台电脑最关键的核心硬件之一,它的性能好坏,直接影响了电脑的运行...  现在Win11系统是非常火热的电脑操作系统,但是win11安装的配置要求比较高,i7 7700是一款使用率非常高的处理器,但...
现在Win11系统是非常火热的电脑操作系统,但是win11安装的配置要求比较高,i7 7700是一款使用率非常高的处理器,但...  CPU故障排除方法...
CPU故障排除方法...  怎么知道主板支持哪些CPU...
怎么知道主板支持哪些CPU...  最近准备DIY准备攒机骚动一族发现英特尔Intel出了一款新的处理器,我给它起了一个好听的绰号爱我,就是福Intel Core i5 9400F,虽然是i5处理器,但是足以维持中阶旗舰之称号。 F的含义福...
最近准备DIY准备攒机骚动一族发现英特尔Intel出了一款新的处理器,我给它起了一个好听的绰号爱我,就是福Intel Core i5 9400F,虽然是i5处理器,但是足以维持中阶旗舰之称号。 F的含义福...  在笔记本兴起的年代,许多玩家都会被那一台台造型酷炫,一体化十足的游戏本所吸引,但是许多DIY爱好者却对游戏本嗤之以鼻,认为它对比DIY主机性价比低下,傻大笨粗移动性也不见...
在笔记本兴起的年代,许多玩家都会被那一台台造型酷炫,一体化十足的游戏本所吸引,但是许多DIY爱好者却对游戏本嗤之以鼻,认为它对比DIY主机性价比低下,傻大笨粗移动性也不见...  2017最新手机cpu性能排行...
2017最新手机cpu性能排行...  玩游戏cpu使用率高怎么解决...
玩游戏cpu使用率高怎么解决...  AMD的第三代锐龙处理器已经发售一段时间了,其凭借不俗的性能和超高的性价比在很多国家受到了广大玩家的热捧,很多人也都情不自禁地喊出了AMD Yes的口号。 关于AMD第三代锐龙的性...
AMD的第三代锐龙处理器已经发售一段时间了,其凭借不俗的性能和超高的性价比在很多国家受到了广大玩家的热捧,很多人也都情不自禁地喊出了AMD Yes的口号。 关于AMD第三代锐龙的性...  有哪些手机CPU测试软件推荐...
有哪些手机CPU测试软件推荐...  怎么看cpu与64位模式是否兼容...
怎么看cpu与64位模式是否兼容...  电脑看视频cpu使用率高怎么回事...
电脑看视频cpu使用率高怎么回事...  下面给出两种系统下的排查步骤,都是一模一样的,只是命令稍有区别! 查消耗cpu最高的进程PID 根据PID查出消耗cpu最高的线程号 根据线程号查出对应的java线程,进行处理。 准备一行...
下面给出两种系统下的排查步骤,都是一模一样的,只是命令稍有区别! 查消耗cpu最高的进程PID 根据PID查出消耗cpu最高的线程号 根据线程号查出对应的java线程,进行处理。 准备一行...  cpu针脚歪了怎么修理...
cpu针脚歪了怎么修理...  笔记本怎么换CPU有哪些要注意的...
笔记本怎么换CPU有哪些要注意的...  千元级CPU因为价格合理又有不错的性能,因此被主流玩家视作是打造游戏平台的首选产品。最近这个价位上最火的莫过于锐龙5 2600和酷睿i5 9400F了,这两款产品在性能上谁更有优势,结...
千元级CPU因为价格合理又有不错的性能,因此被主流玩家视作是打造游戏平台的首选产品。最近这个价位上最火的莫过于锐龙5 2600和酷睿i5 9400F了,这两款产品在性能上谁更有优势,结...  cpu和内存条不兼容怎么办解决教程...
cpu和内存条不兼容怎么办解决教程...  威刚作为老牌的内存厂商,在芝奇推出了皇家戟这么漂亮的内存之后,似乎并没有什么动作,至少在RGB方向上的动作并不多,但是平心而论,这种大厂之间的竞争,还是需要一个对标的...
威刚作为老牌的内存厂商,在芝奇推出了皇家戟这么漂亮的内存之后,似乎并没有什么动作,至少在RGB方向上的动作并不多,但是平心而论,这种大厂之间的竞争,还是需要一个对标的...  cpu与风扇硅胶拆不下来解决方法教程...
cpu与风扇硅胶拆不下来解决方法教程...  CPU超频导致系统蓝屏怎么办...
CPU超频导致系统蓝屏怎么办...  笔记本电脑CPU天梯图,笔记本电脑CPU排行,是按照CPU的跑分进行排序,进行综合性能对比。可以一定程度上反应CPU的...
笔记本电脑CPU天梯图,笔记本电脑CPU排行,是按照CPU的跑分进行排序,进行综合性能对比。可以一定程度上反应CPU的...  在购买笔记本电脑时我们经常会看到商家在文案中写了某某型号的标压处理器,而有些又是某某型号的低压处理器,那CPU的标压和低压到底有什么区别呢?标压是不是一定就比低压好?...
在购买笔记本电脑时我们经常会看到商家在文案中写了某某型号的标压处理器,而有些又是某某型号的低压处理器,那CPU的标压和低压到底有什么区别呢?标压是不是一定就比低压好?...  Intel处理器命名规则是怎样的...
Intel处理器命名规则是怎样的...  笔记本cpu温度90度怎么解决...
笔记本cpu温度90度怎么解决...  cpu风扇怎么拆开加油...
cpu风扇怎么拆开加油...  玩游戏对电脑CPU、显卡和内存等硬件都是一种考验,尤其是大型3D游戏,如果有任何一个硬件出现瓶颈都可能导致游戏体验下降,大家都知道显卡对于游戏性能好坏起着非常大的作用,...
玩游戏对电脑CPU、显卡和内存等硬件都是一种考验,尤其是大型3D游戏,如果有任何一个硬件出现瓶颈都可能导致游戏体验下降,大家都知道显卡对于游戏性能好坏起着非常大的作用,...  手机cpu温度过高怎么办...
手机cpu温度过高怎么办...  超频3cpu风扇怎么拆...
超频3cpu风扇怎么拆...  Win10系统CPU使用率高的解决方法...
Win10系统CPU使用率高的解决方法...  cpu性能弱玩不了游戏有没有解决方法...
cpu性能弱玩不了游戏有没有解决方法...  CPU是一块超大规模的集成电路,是一台计算机的运算核心(Core)和控制核心( Control Unit)。它的功能主要是解释计算...
CPU是一块超大规模的集成电路,是一台计算机的运算核心(Core)和控制核心( Control Unit)。它的功能主要是解释计算...  酷睿七代可以升级win11吗?我们都知道Win11系统安装是有配置要求的,最低配置要求八代酷睿,很多使用七代的用户就...
酷睿七代可以升级win11吗?我们都知道Win11系统安装是有配置要求的,最低配置要求八代酷睿,很多使用七代的用户就...  2018年年底2019年年初,Intel推出了第九代桌面级别的酷睿处理器,配合LGA 1151脚座的300系列主板,从目前来看从i3-i7都有上市销售,个别型号相比上一代的处理器还要便宜且性能更好。...
2018年年底2019年年初,Intel推出了第九代桌面级别的酷睿处理器,配合LGA 1151脚座的300系列主板,从目前来看从i3-i7都有上市销售,个别型号相比上一代的处理器还要便宜且性能更好。...  最近碰到一个令人差异的情况,就是我的电脑在运行游戏的时候总是卡顿,但是同样是i7+GTX 1060显卡的配置,小明同学的电脑却是非常的流畅,这到底是怎么个情况呢? 为什么会发现这...
最近碰到一个令人差异的情况,就是我的电脑在运行游戏的时候总是卡顿,但是同样是i7+GTX 1060显卡的配置,小明同学的电脑却是非常的流畅,这到底是怎么个情况呢? 为什么会发现这...  笔记本cpu硅胶涂抹方法...
笔记本cpu硅胶涂抹方法...  xp系统怎么看CPU的性能和型号...
xp系统怎么看CPU的性能和型号...  Mscorsvw进程CPU占用高怎么解决...
Mscorsvw进程CPU占用高怎么解决...  4月23日,英特尔推出了全新的第九代智能酷睿高性能移动版处理器(H系列),该系列处理器专为游戏玩家和创作者而设计,将用户体验提升至新的高度。 英特尔高端和游戏笔记本电脑...
4月23日,英特尔推出了全新的第九代智能酷睿高性能移动版处理器(H系列),该系列处理器专为游戏玩家和创作者而设计,将用户体验提升至新的高度。 英特尔高端和游戏笔记本电脑...  主板cpu供电不足怎么办...
主板cpu供电不足怎么办...