
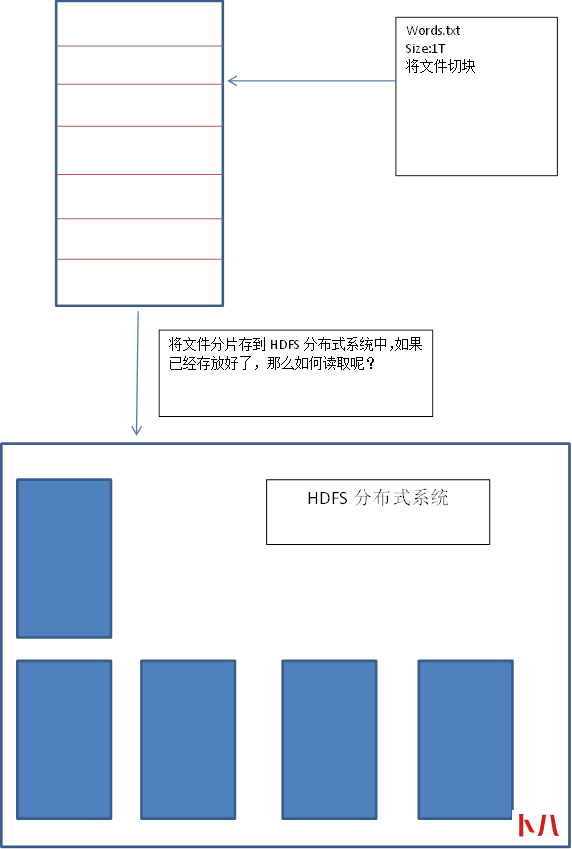
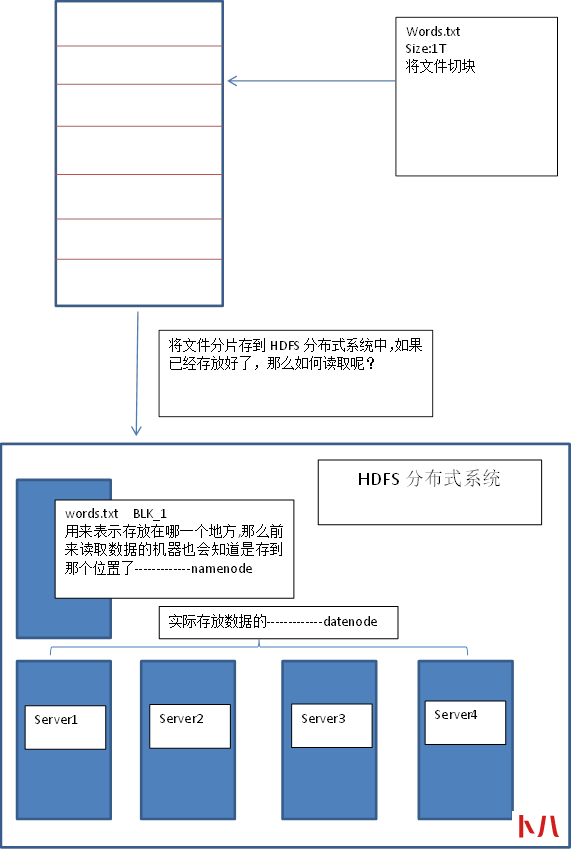
两个角色:
Namenode负责管理文件的名称空间
Datanode负责存储数据,会定时向namenode进行汇报,是一个list。
补充概念:
- HDFS的块(block)
- 文件的分块(chunk)
- 网络拓扑
- 机架感知
1、HDFS的块(block)
磁盘是分数据块的,默认大小512B
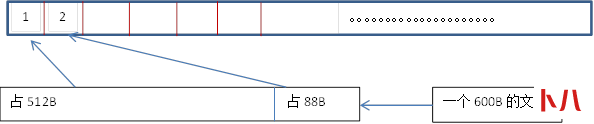
磁盘:一个600B的文件,分成两个部分一个是512B,一个是88B。
512B存到1号分块中,88B存到2号分块中。下次如果有一个新的文件,是不会再补充到2号分块中,只会往后继续存放。
HDFS:抽象在磁盘之上,有上述磁盘类似的概念。
但有不同点:
- block默认大小,Hadoop1.x 64M Hadoop2.x 128M。
- HDFS:一个200M的文件,分成两个部分一个是128M,一个是72M。
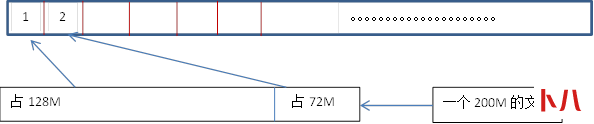
HDFS分块大小为什么是128M?答案:最小化寻址时间
例子:假如我们的磁盘速率是100M/s,磁头寻址时间是10ms,在整个传输过程中,让寻址时间仅仅占传输时间的1%,传输的文件大小是100M。
100在2的N次方中离128最近。
2、文件的分块(chunk)
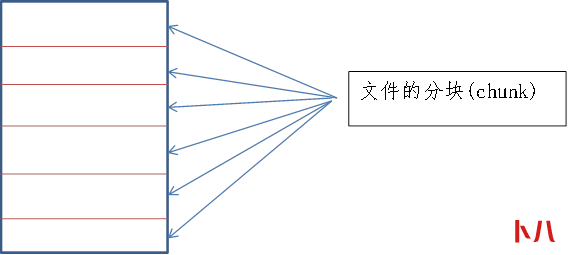
Chunk默认的大小和block是一样的。可以调整,建议和block一样。
3、网络拓扑
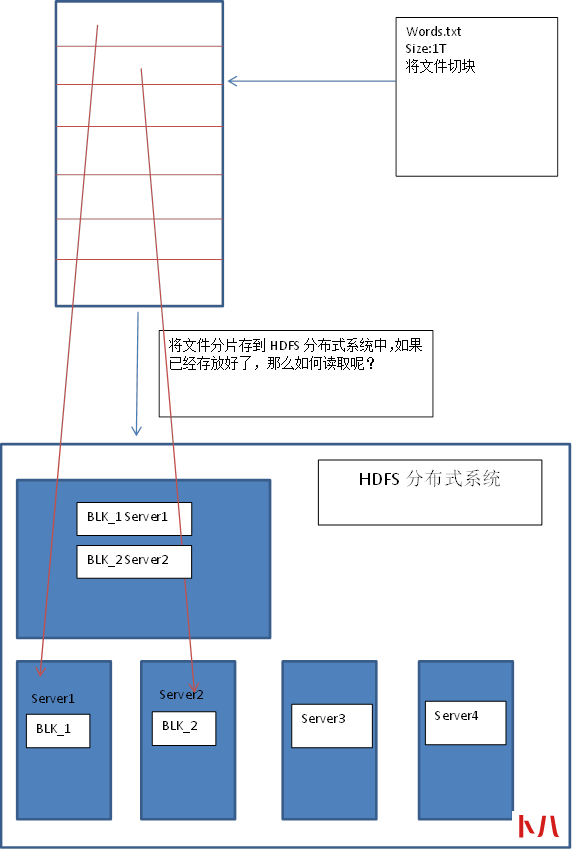
每个节点是有可能出现问题的,比如Server1这个节点突然断电了,那么就会存在丢失数据的情况。如何最大程度避免这个问题呢?
Hadoop选择备份数据,将BLK_1备份到多台机器上,比如三台机器上,一个机器出问题了,还有两个机器可以使用。


 联通卡网速提升增强信号方法分享 电信卡和移动卡他们的机制是不一样的,...
联通卡网速提升增强信号方法分享 电信卡和移动卡他们的机制是不一样的,...  微信黑号是什么?每次参加活动时领红包时就会提示发放失败,已被微信拦截...
微信黑号是什么?每次参加活动时领红包时就会提示发放失败,已被微信拦截... 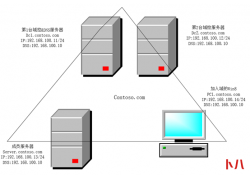 前言 我们按照下图来创建第一个林中的第一个域。创建方法为先安装一台Win...
前言 我们按照下图来创建第一个林中的第一个域。创建方法为先安装一台Win...  很多玩群晖的同学都知道,黑群晖是不能随便升级的,一般是禁用系统升级的,现在花王网络教大家一招简单的方法...
很多玩群晖的同学都知道,黑群晖是不能随便升级的,一般是禁用系统升级的,现在花王网络教大家一招简单的方法...  Alook浏览器使用方法教程...
Alook浏览器使用方法教程...  很多群晖群好友提出出一篇关于EMBY的全面教程,今天我就有求必应,来一篇关于EMBY的教程,同时配合KODI打造家庭影...
很多群晖群好友提出出一篇关于EMBY的全面教程,今天我就有求必应,来一篇关于EMBY的教程,同时配合KODI打造家庭影...  对于家里淘汰掉的老旧电脑,你都怎么处置?删光资料然后转手还是闲置?对...
对于家里淘汰掉的老旧电脑,你都怎么处置?删光资料然后转手还是闲置?对...  说起下载工具有非常多,而下载种子工具比较优秀也就那么几款,国内常见的是迅雷和百度云,但这两家都要会员,...
说起下载工具有非常多,而下载种子工具比较优秀也就那么几款,国内常见的是迅雷和百度云,但这两家都要会员,...  想要通过外网访问群晖,你得满足以下几个条件:1、有公网IP2、路由器拨号3、申请动态域名1、首先你得检查你是否...
想要通过外网访问群晖,你得满足以下几个条件:1、有公网IP2、路由器拨号3、申请动态域名1、首先你得检查你是否...  群晖强大的工具Docker应用篇三:安装百度云baidupcs-go Web版大家在使用百度网盘的时候,应该会被百度网盘的下载速度...
群晖强大的工具Docker应用篇三:安装百度云baidupcs-go Web版大家在使用百度网盘的时候,应该会被百度网盘的下载速度...  打开游戏时总是出现“需要新应用打开此MS-gamingoverlay”...
打开游戏时总是出现“需要新应用打开此MS-gamingoverlay”...  上网的时候,发现某个网页上的视频、音乐很合你心意,想保存下来,却发现网页不让你保存,或者要你安装什么客户端,好烦哦~怎么办呢? 今天老司机教你几种方法,可以无限制地...
上网的时候,发现某个网页上的视频、音乐很合你心意,想保存下来,却发现网页不让你保存,或者要你安装什么客户端,好烦哦~怎么办呢? 今天老司机教你几种方法,可以无限制地... 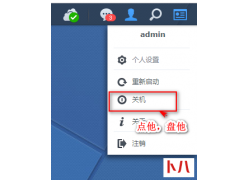 群晖关机不是很容易吗,就右上角点击关机就成,或者手机群晖助手右上角点击也行,非常方便,这操作SO easy,你是不...
群晖关机不是很容易吗,就右上角点击关机就成,或者手机群晖助手右上角点击也行,非常方便,这操作SO easy,你是不...  猫盘群晖系统正确打开方式很多小伙伴刚收到猫盘不知道如何用,刷机群晖的猫盘如何用呢,它和一般的网络设备不...
猫盘群晖系统正确打开方式很多小伙伴刚收到猫盘不知道如何用,刷机群晖的猫盘如何用呢,它和一般的网络设备不... 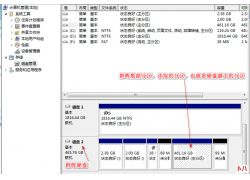 Windows系统下读取群晖文件方法天有不测风云,偶尔有一天群晖系统崩溃或者重装系统出现问题需变砖,群晖硬盘又有...
Windows系统下读取群晖文件方法天有不测风云,偶尔有一天群晖系统崩溃或者重装系统出现问题需变砖,群晖硬盘又有... 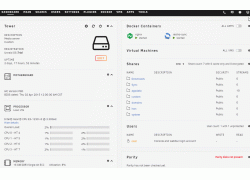 玩unraid主要看重的是多媒体的功能,那么显卡加速就显得非常重要,显卡分为核显和独显,本文介绍的是通过安装核...
玩unraid主要看重的是多媒体的功能,那么显卡加速就显得非常重要,显卡分为核显和独显,本文介绍的是通过安装核... 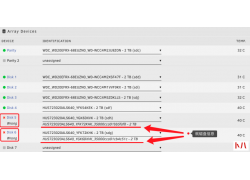 我们在使用unraid时有可能因为某些原因,需要更换硬盘,比如硬盘坏了,又比如更换更大容器的硬盘,这样,如图更...
我们在使用unraid时有可能因为某些原因,需要更换硬盘,比如硬盘坏了,又比如更换更大容器的硬盘,这样,如图更... 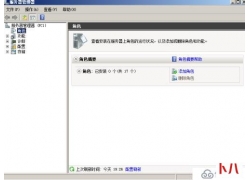 打开服务器管理器--角色--添加角色--选择Active Directory域服务 下一步 一直到安...
打开服务器管理器--角色--添加角色--选择Active Directory域服务 下一步 一直到安...  前言:使用群晖的同学一定会接触SSH代码,比如安装第三方插件,尤其是使用docker时需要,因为群晖的docker操作界面...
前言:使用群晖的同学一定会接触SSH代码,比如安装第三方插件,尤其是使用docker时需要,因为群晖的docker操作界面...  PVE安装教程介绍:PVE是专业的虚拟机平台,提供一个家庭设备集中管理平台,你可以利用它安装任何你想要的系统,...
PVE安装教程介绍:PVE是专业的虚拟机平台,提供一个家庭设备集中管理平台,你可以利用它安装任何你想要的系统,... 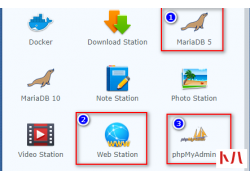 很多朋友想建立自已的网站,搭建自已的网站就必需有一台服务器,服务器可以是微软的WIN服务器也可以是非常通用...
很多朋友想建立自已的网站,搭建自已的网站就必需有一台服务器,服务器可以是微软的WIN服务器也可以是非常通用...  1、问:黑群晖是否需要一个SSD当做系统盘?答:群晖系统跟Windows不同,Windows有个盘要当成系统盘,而群晖会在每个...
1、问:黑群晖是否需要一个SSD当做系统盘?答:群晖系统跟Windows不同,Windows有个盘要当成系统盘,而群晖会在每个...  PVE安装EMBY支持硬解码很多用J3455安装群晖的小伙伴,是不是有以下这个困扰:安装DS3617xs稳定流畅,但是不支持硬件解...
PVE安装EMBY支持硬解码很多用J3455安装群晖的小伙伴,是不是有以下这个困扰:安装DS3617xs稳定流畅,但是不支持硬件解...  qBittorrent 的配置优化技巧,详细图文,学习一次,即可掌握。这是一款非常优秀的PT下载工具,由于其开放性和易玩性...
qBittorrent 的配置优化技巧,详细图文,学习一次,即可掌握。这是一款非常优秀的PT下载工具,由于其开放性和易玩性... 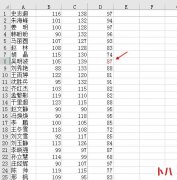 简介:在Excel中,要查找几行几列的数据并把结果显示出来,可以使用index函数。 如图:我要查找第8行第4列的数据并把结果在旁边空单元格显示出来 第一步:在旁边任意一个空单元格...
简介:在Excel中,要查找几行几列的数据并把结果显示出来,可以使用index函数。 如图:我要查找第8行第4列的数据并把结果在旁边空单元格显示出来 第一步:在旁边任意一个空单元格...  在办公室的同志对这个场景深有体会,比如公司盘点仓库后,实物盘点卡数据要录入到数据表,但是录入的人员很多...
在办公室的同志对这个场景深有体会,比如公司盘点仓库后,实物盘点卡数据要录入到数据表,但是录入的人员很多... 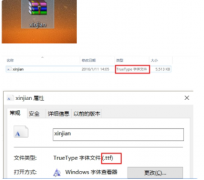 win10系统字体是宋体的,时间一长,感觉腻了,想win10电脑字体设置楷体,换一下心情.但问题来了,win10电脑字体怎么设置楷...
win10系统字体是宋体的,时间一长,感觉腻了,想win10电脑字体设置楷体,换一下心情.但问题来了,win10电脑字体怎么设置楷... 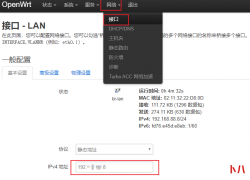 竞斗云openwrt使用指南很多小伙伴没有接触过openwrt路由器,初次见面会被各种菜单搞得不知所措,而竞斗云现在支持刷...
竞斗云openwrt使用指南很多小伙伴没有接触过openwrt路由器,初次见面会被各种菜单搞得不知所措,而竞斗云现在支持刷...  Transmission是一款非常强大的下载工具,它是downloads station的鼻祖,功能强大的下载工具,下载种子和做种都是很快的,...
Transmission是一款非常强大的下载工具,它是downloads station的鼻祖,功能强大的下载工具,下载种子和做种都是很快的,...  用了三年的手机刚过保修期就坏了,想着处理掉,刚好碰到在小区收旧手机的...
用了三年的手机刚过保修期就坏了,想着处理掉,刚好碰到在小区收旧手机的...  想看美剧怎么办,选择YOUKU或者腾迅国内的平台,不但要会员而且更新慢,广告满天飞,怎么不爽怎么来,怎么办,群...
想看美剧怎么办,选择YOUKU或者腾迅国内的平台,不但要会员而且更新慢,广告满天飞,怎么不爽怎么来,怎么办,群...  利用新用户账户登录域控 除了域Administrators等少数组内的成员外,其他一般域...
利用新用户账户登录域控 除了域Administrators等少数组内的成员外,其他一般域... 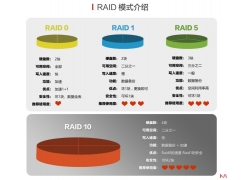 群晖的磁盘阵列群晖不像WIN系统,插上硬盘就能用,而是需先组建RAID GROUP,然后新建存储空间,才能使用,这里讲的...
群晖的磁盘阵列群晖不像WIN系统,插上硬盘就能用,而是需先组建RAID GROUP,然后新建存储空间,才能使用,这里讲的...  电脑wps没保存关闭了怎么恢复数据?很多用户都遇到过忘记保存wps文件,然后直接关闭,导致自己辛苦编辑的文件又...
电脑wps没保存关闭了怎么恢复数据?很多用户都遇到过忘记保存wps文件,然后直接关闭,导致自己辛苦编辑的文件又...  网络唤醒,这看起来很悬的东西,其实原理很简单,就是通过路由器将开机指令到指定设备的网卡,通过网卡进行开...
网络唤醒,这看起来很悬的东西,其实原理很简单,就是通过路由器将开机指令到指定设备的网卡,通过网卡进行开...  想要通过手机A获取手机B的位置信息,首先需要为手机B绑定云账号,并开启“...
想要通过手机A获取手机B的位置信息,首先需要为手机B绑定云账号,并开启“...  PVE安装LibreELEC-KODI的linux版LibreELEC是一个免费开源的轻量级“Just enough OS”Linux发行版,它属于KODI的一个分支版本,功...
PVE安装LibreELEC-KODI的linux版LibreELEC是一个免费开源的轻量级“Just enough OS”Linux发行版,它属于KODI的一个分支版本,功...  创建更多的域控制器 如果一个域内有多个域控制器,可以有如下好处。 提高用...
创建更多的域控制器 如果一个域内有多个域控制器,可以有如下好处。 提高用...  此文将全面阐述如何直通各硬件设备给虚拟机的方法,在这里,我们将展开直通网卡和硬盘的方法,其中网卡又分直...
此文将全面阐述如何直通各硬件设备给虚拟机的方法,在这里,我们将展开直通网卡和硬盘的方法,其中网卡又分直...  PVE配置免费证书装了PVE的小伙伴们需要使用https来访问,开始访问老是提示不安全,怎么办呢,这里小编为大家提供配...
PVE配置免费证书装了PVE的小伙伴们需要使用https来访问,开始访问老是提示不安全,怎么办呢,这里小编为大家提供配... 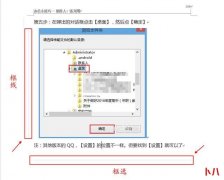 简介:在编辑word文档的过程中,经常会碰到文档中有许多灰色的直线,可以选中,可以拖动,但无法去除。 工具:Word2016 如图所示:文档中的灰色直线 原因:这些灰色的直线实际上是...
简介:在编辑word文档的过程中,经常会碰到文档中有许多灰色的直线,可以选中,可以拖动,但无法去除。 工具:Word2016 如图所示:文档中的灰色直线 原因:这些灰色的直线实际上是...  电脑声音可以通过连接到本电脑上的音箱或耳机播放出来,有时因为工作需要,需要将A电脑上的声音,实时同步分享到局域网内B电脑的音箱上进行播放,该如何实现呢?下面就跟着我...
电脑声音可以通过连接到本电脑上的音箱或耳机播放出来,有时因为工作需要,需要将A电脑上的声音,实时同步分享到局域网内B电脑的音箱上进行播放,该如何实现呢?下面就跟着我...  浏览器自动弹出网页怎么处理...
浏览器自动弹出网页怎么处理...  前面讲过开启核心显卡来加速EMBY,详细见unraid系统五:开启Intel核显并加速EMBY,现在本文要讲的是通过使用独立显卡...
前面讲过开启核心显卡来加速EMBY,详细见unraid系统五:开启Intel核显并加速EMBY,现在本文要讲的是通过使用独立显卡...  首先大家先看一张PS前后的照片对比图。 感觉是不是照片的效果明显就不同了呢? 下面,阳阳老师就来为各位小伙伴们分步的进行讲解。 仿制图章工具 之前在讲到修复老照片的时候,...
首先大家先看一张PS前后的照片对比图。 感觉是不是照片的效果明显就不同了呢? 下面,阳阳老师就来为各位小伙伴们分步的进行讲解。 仿制图章工具 之前在讲到修复老照片的时候,...  王者荣耀段位分别是什么?...
王者荣耀段位分别是什么?...  wallpaper engineer怎么拖进度条?在Steam中,很多用户喜欢使用wallpaper engineer下载壁纸视频,那怎么拖动wallpaper engineer视频...
wallpaper engineer怎么拖进度条?在Steam中,很多用户喜欢使用wallpaper engineer下载壁纸视频,那怎么拖动wallpaper engineer视频... 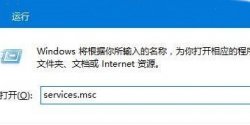 微软带的系统一般都会自带一个应用商店,用户可以在这个应用商店里下载所需要的软件,如果应用商店无法下载了...
微软带的系统一般都会自带一个应用商店,用户可以在这个应用商店里下载所需要的软件,如果应用商店无法下载了...  现在生活节奏很快,很多人都没有时间外出觅食,外卖成为这类人群的福音,在家在公司想吃什么就点什么。用美团...
现在生活节奏很快,很多人都没有时间外出觅食,外卖成为这类人群的福音,在家在公司想吃什么就点什么。用美团...  钉钉怎么使用局域网传输文件...
钉钉怎么使用局域网传输文件...