
今天,我们就利用 Python 定制一款“飞花令”小程序:给定一个关键字或者关键词,就能够返回许多含有这个关键字的诗句,跟朋友玩再也不怕输了!
网页分析
要利用爬虫完成这项工作需要先选择一个合适的网站,这里我们选择了 古诗文网https://www.gushiwen.cn/
在右上角的方框中输入关键词,如酒,就能够返回相应的结果: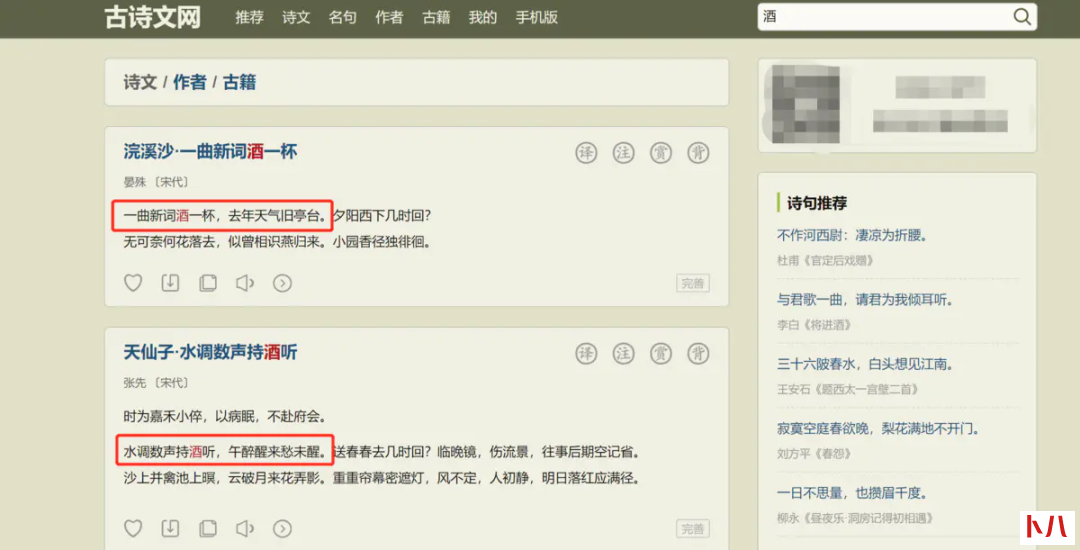
我们注意到,返回的结果是一整首诗或词,关键字所在的句子仅为其中一句。后面我们爬取信息时也需要做到过滤。
往下翻页后会发现只能获取前 2 页内容,到第 3 页会出现以下提示: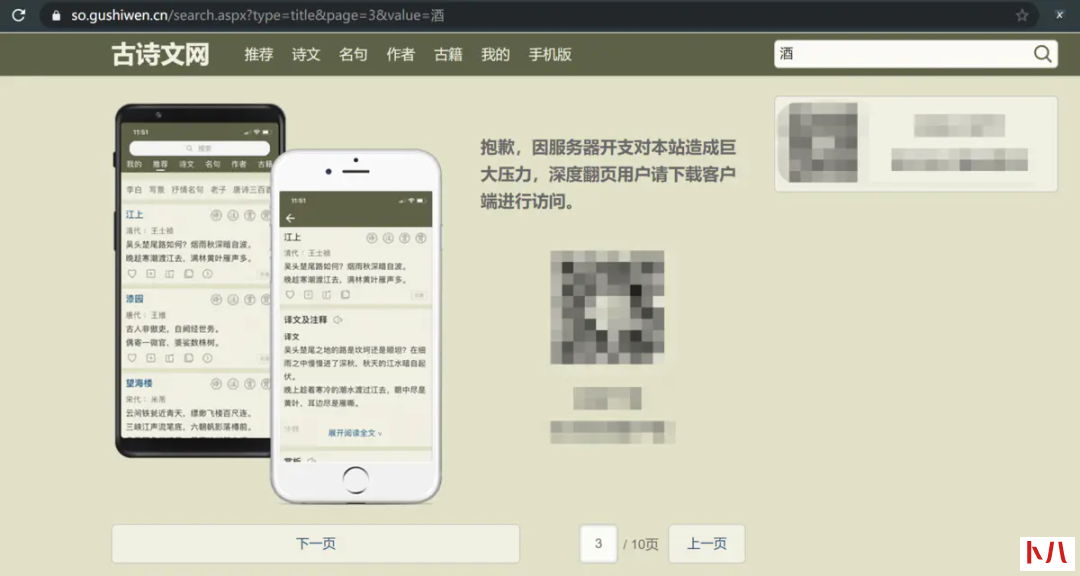
也就是说要完整获取全部诗文需要下载 App,本文简化问题只爬取前 2 页的内容,后续有机会再分享 App 相关爬虫推文。在翻页的过程中我们注意一下 URL 的改变:
“第 1 页:
https://so.gushiwen.cn/search.aspx?value=酒第 2 页:
”https://so.gushiwen.cn/search.aspx?type=title&page=2&value=酒
其中经过测试 type=title 可以去除,而page=2 显然是页码,那么 page=1 能否获取到第 1 页呢?
答案是可以的,因此不需要用 requests 的 post 请求,直接 get 下面的 URL 就可到达指定页面:https://so.gushiwen.cn/search.aspx?page=页码&value=关键字
大致分析完就可以写代码了
代码实现
首先导入库,设置请求头
import requests
from lxml import html
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}
以关键字酒为例,尝试获取第一页全部内容:
import requests
from lxml import html
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}
html_data = requests.get('https://so.gushiwen.cn/search.aspx?page=1&value=酒', headers=headers).text
print(html_data)
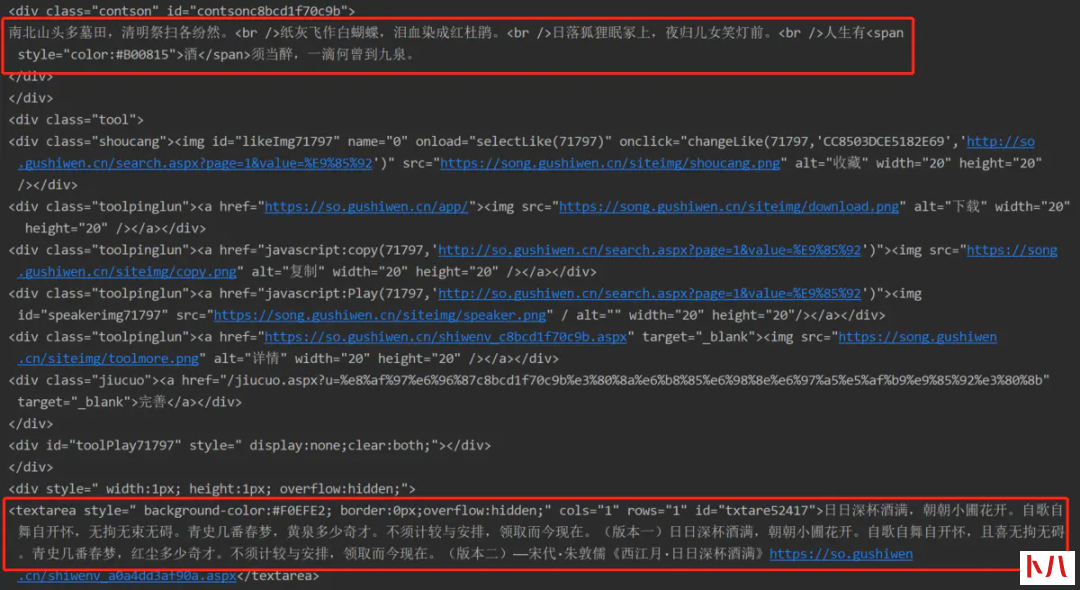
返回的文本中有我们需要的内容,说明组合而成的请求是没有问题的。接下来就可以解析文本获取具体内容了,本文采用 Xpath:
selector = html.fromstring(html_data)
poets = selector.xpath("/html/body/div[2]/div[1]/div[@class='sons']")
for poet in poets:
title = ''.join(poet.xpath("div[1]/p[1]/a/b//text()")).strip()
print(title)

诗人和朝代被分隔至两行,说明之间存在换行符及空格,可以用包含.strip()的列表推导式去除:
for poet in poets:
title = ''.join(poet.xpath("div[1]/p[1]/a/b//text()")).strip()
source = ''.join(poet.xpath('div[1]/p[2]//text()'))
source = ''.join([i.strip() for i in source])
print(title, source)

最后是对诗句的解析。为了获取关键字真正在的句子,我们要通过句号或者问号将整首诗断开成多个完整句:
for poet in poets:
title = ''.join(poet.xpath("div[1]/p[1]/a/b//text()")).strip()
source = ''.join(poet.xpath('div[1]/p[2]//text()'))
source = ''.join([i.strip() for i in source])
contents = ''.join(poet.xpath('div[1]/div[@class="contson"]//text()')).strip().replace('\n', '。').replace('?', '。').split('。')
print(title, source, contents)

对每一首诗逐渐判断是否包含关键字:
for poet in poets:
title = ''.join(poet.xpath("div[1]/p[1]/a/b//text()")).strip()
source = ''.join(poet.xpath('div[1]/p[2]//text()'))
source = ''.join([i.strip() for i in source])
contents = ''.join(poet.xpath('div[1]/div[@class="contson"]//text()')).strip().replace('\n', '。').replace('?', '。').split('。')
content_lst = []
for i in contents:
if '酒' in i:
content = i.strip() + '。'
content_lst.append(content)
# 有的诗可能有两句都包含关键字,这两句诗就都是需求
if not content_lst: # 有可能只有题目中含有关键词,这种诗就跳过
continue
for j in list(set(content_lst)): # 有可能有的诗虽然有两句都包含关键字,但这两句是一样的,需要去重
print(j, title, source)

大部分需求已经满足,最后只需要利用循环结构组装 URL 达到范围多页的目的,同时关键字可以修改为 input 交互输入,代码如下:
import requests
from lxml import html
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}
def poet_content(keyword,num,url):
html_data = requests.get(url, headers=headers).text
selector = html.fromstring(html_data)
poets = selector.xpath("/html/body/div[2]/div[1]/div[@class='sons']")
for poet in poets:
title = ''.join(poet.xpath("div[1]/p[1]/a/b//text()")).strip()
source = ''.join(poet.xpath('div[1]/p[2]//text()'))
source = ''.join([i.strip() for i in source])
contents = ''.join(poet.xpath('div[1]/div[@class="contson"]//text()')).strip().replace('\n', '。').replace('?','。').split('。')
content_lst = []
for i in contents:
if keyword in i:
content = i.strip() + '。'
content_lst.append(content)
if not content_lst:
continue
for j in list(set(content_lst)):
print(num, j)
print(f'<{title}>', source)
print('')
num += 1
return num
if __name__ == '__main__':
keyword = input('> 请输入关键词: ')
print('')
num = 1
for i in range(1, 3):
url = f'https://so.gushiwen.org/search.aspx?page={i}&value={keyword}'
num = poet_content(keyword, num, url)

至此,我们就通过 Python 爬虫就成功制作了一款“飞花令”小工具,感兴趣的读者可以自己尝试一下!


 本人已习惯使用Linux的命令,回过头来使用Windows原生Cmd感觉很不爽。也有很多...
本人已习惯使用Linux的命令,回过头来使用Windows原生Cmd感觉很不爽。也有很多...  pdf是一种便携式文档格式,由Adobe公司设计。因为不受平台限制,且方便保存和...
pdf是一种便携式文档格式,由Adobe公司设计。因为不受平台限制,且方便保存和...  在前几个月,Thinkphp连续爆发了多个严重漏洞。由于框架应用的广泛性,漏洞影响非常大。为了之后更好地防御和应对此框架漏洞,天融信阿尔法实验室对Thinkphp框架进行了详细地分析,...
在前几个月,Thinkphp连续爆发了多个严重漏洞。由于框架应用的广泛性,漏洞影响非常大。为了之后更好地防御和应对此框架漏洞,天融信阿尔法实验室对Thinkphp框架进行了详细地分析,...  UEFI Firmware Parser,即UEFI固件解析器,它是一个简单的脚本模块集合。它可以解析、提取并重建UEFI固件卷宗。其中包括针对BIOS、OptionROM、Intel ME和其他格式的解析模块。 工具安装 这个模...
UEFI Firmware Parser,即UEFI固件解析器,它是一个简单的脚本模块集合。它可以解析、提取并重建UEFI固件卷宗。其中包括针对BIOS、OptionROM、Intel ME和其他格式的解析模块。 工具安装 这个模...  一开始打开github,一看是.net代码,一脸懵。第二天起来于心不甘,就想试试能不能根据代码逻辑以及函数名称分析一波算法。于是做了一波曲折但有趣的研究。现在将工具分享出来,希...
一开始打开github,一看是.net代码,一脸懵。第二天起来于心不甘,就想试试能不能根据代码逻辑以及函数名称分析一波算法。于是做了一波曲折但有趣的研究。现在将工具分享出来,希...  hdwiki这套系统分为两部分通读,它的代码逻辑非常有趣。一部分为程序路由,...
hdwiki这套系统分为两部分通读,它的代码逻辑非常有趣。一部分为程序路由,...  在前面内容的基础上,我们在UserDao中编写一个方法 在UserMappper中编写 编写测试类,这个测试类的查询条件全部不为空 查看结果 我们设置部分条件是空的,例如用户角色为空 我们修改...
在前面内容的基础上,我们在UserDao中编写一个方法 在UserMappper中编写 编写测试类,这个测试类的查询条件全部不为空 查看结果 我们设置部分条件是空的,例如用户角色为空 我们修改...  Python的定位非常明确,它是一种简单易用但又专业严谨的语言。或者说叫胶水语言。普通人也很容易入门。Python可以把各个基本程序拼接在一起协同运作。任何一个人只要愿意学习,可...
Python的定位非常明确,它是一种简单易用但又专业严谨的语言。或者说叫胶水语言。普通人也很容易入门。Python可以把各个基本程序拼接在一起协同运作。任何一个人只要愿意学习,可...  一、PLC的定义与分类PLC是以微处理器为基础,综合了计算机技术、自动控制技术和通信技术,用面向控制过程面向用户的自然语言编程,适应工业环境,简单易懂、操作方便、可靠性高...
一、PLC的定义与分类PLC是以微处理器为基础,综合了计算机技术、自动控制技术和通信技术,用面向控制过程面向用户的自然语言编程,适应工业环境,简单易懂、操作方便、可靠性高...  今天在搭完一个新的虚拟机后,在使用sudo yum -y update 的情况下,出现了提示...
今天在搭完一个新的虚拟机后,在使用sudo yum -y update 的情况下,出现了提示...  想要了解Spring中的AOP,我们先了解下代理模式 在生活中,我们经常会遇到代理,比如中介、婚介、黄牛、代理办证等等,这些代理会比我更有效率或者更好的完成我们想做的事情,可无...
想要了解Spring中的AOP,我们先了解下代理模式 在生活中,我们经常会遇到代理,比如中介、婚介、黄牛、代理办证等等,这些代理会比我更有效率或者更好的完成我们想做的事情,可无...  承接上一个练习,我们看一个小内容:resultMap自动映射级别 在之前这个例子中,我们可以看到User类中的userPassword属性和Address类中的userId属性均未在resultMap中进行匹配 那么我们编写一个...
承接上一个练习,我们看一个小内容:resultMap自动映射级别 在之前这个例子中,我们可以看到User类中的userPassword属性和Address类中的userId属性均未在resultMap中进行匹配 那么我们编写一个...  各位在企业中做Web漏洞扫描或者 渗透 测试的朋友,可能会经常遇到需要对图...
各位在企业中做Web漏洞扫描或者 渗透 测试的朋友,可能会经常遇到需要对图... 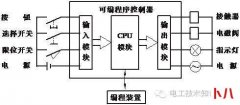 第一章可编程控制器简介 可编程序控制器,英文称Programmable Controller,简称PC。但由于PC容易和个人计算机(Personal Computer)混淆,故人们仍习惯地用PLC作为可编程序控制器的缩写。它是...
第一章可编程控制器简介 可编程序控制器,英文称Programmable Controller,简称PC。但由于PC容易和个人计算机(Personal Computer)混淆,故人们仍习惯地用PLC作为可编程序控制器的缩写。它是...  现在大部分搞前端的应该还是这样写 CSS 的: .mock { margin :auto; font-size : 16px ;...
现在大部分搞前端的应该还是这样写 CSS 的: .mock { margin :auto; font-size : 16px ;...  缓存设计可谓老生常谈了,早些时候都是采用 memcache ,现在大家更多倾向使用...
缓存设计可谓老生常谈了,早些时候都是采用 memcache ,现在大家更多倾向使用...  软件简单说明 DEDE标签精灵(Dede label elves) 是一款标签生成工具,可以快速...
软件简单说明 DEDE标签精灵(Dede label elves) 是一款标签生成工具,可以快速...  HTML一键打包EXE工具(HTML封装EXE,桌件)能把任意HTML项目(网址)一键打包为单个...
HTML一键打包EXE工具(HTML封装EXE,桌件)能把任意HTML项目(网址)一键打包为单个...  APP版本:V8.2.4.2961 工具:burpsuite,xposed,frida,儿童手表 0x1.接口分析 这里我...
APP版本:V8.2.4.2961 工具:burpsuite,xposed,frida,儿童手表 0x1.接口分析 这里我...  有一个群友在群里问个如何快速搭建一个搜索引擎,在搜索之后我看到了这个...
有一个群友在群里问个如何快速搭建一个搜索引擎,在搜索之后我看到了这个...  本文只针对比较流行的跳转型暗链作为研究对象,其他类型的暗链暂时不做讨...
本文只针对比较流行的跳转型暗链作为研究对象,其他类型的暗链暂时不做讨...  这一节介绍PLC的数据通信,数据通信在PLC的学习中是属于比较高级的应用,对于初学者来说觉得还是有一定的难度,许多朋友一接触通信就感觉头大,各种的云山雾罩,想要学习却又无...
这一节介绍PLC的数据通信,数据通信在PLC的学习中是属于比较高级的应用,对于初学者来说觉得还是有一定的难度,许多朋友一接触通信就感觉头大,各种的云山雾罩,想要学习却又无...  易语言是一个自主开发,适合国情,不同层次不同专业的人员易学易用的汉语...
易语言是一个自主开发,适合国情,不同层次不同专业的人员易学易用的汉语... 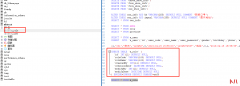 之前已经完成了MyBatis的增删改查,现在我们来处理一个问题,如果再JavaBean中有一个映射属性是个复杂类型比如在User用户表中,有一个Role角色属性。我们该如何处理,为了解决这个问...
之前已经完成了MyBatis的增删改查,现在我们来处理一个问题,如果再JavaBean中有一个映射属性是个复杂类型比如在User用户表中,有一个Role角色属性。我们该如何处理,为了解决这个问...  之前实现了用户的增删改,实现了一个简单的数据统计功能,但实际上查询的功能更为常见,我们看一下数据查询功能 首先我们根据ID编号查询一个数据,编辑对应的Dao和Mapper Mapper 编写对...
之前实现了用户的增删改,实现了一个简单的数据统计功能,但实际上查询的功能更为常见,我们看一下数据查询功能 首先我们根据ID编号查询一个数据,编辑对应的Dao和Mapper Mapper 编写对... 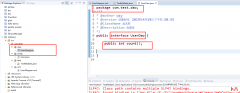 我们已经完成MyBatis的基础环境搭建,并完成了一种查询,这种方式是一种旧版本方式,还有一种官方推荐的方式,我们来看一下 我们创建一个接口 这个位置我们做了一个更改 在测试方...
我们已经完成MyBatis的基础环境搭建,并完成了一种查询,这种方式是一种旧版本方式,还有一种官方推荐的方式,我们来看一下 我们创建一个接口 这个位置我们做了一个更改 在测试方...  学习 Python 这么久了,今天我们来聊聊如何利用 Python 提升办公效率,在工作中...
学习 Python 这么久了,今天我们来聊聊如何利用 Python 提升办公效率,在工作中... 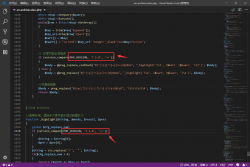 相信很多用DedeCMS的站友们都会为给文章做内链觉得繁琐,对于很多插件可能...
相信很多用DedeCMS的站友们都会为给文章做内链觉得繁琐,对于很多插件可能...  文 | 李晓飞 来源:Python 技术「ID: pythonall」 上一期,谈了如何用Python 打造运营...
文 | 李晓飞 来源:Python 技术「ID: pythonall」 上一期,谈了如何用Python 打造运营...  话说搞安全的大佬们都非常忙,自己在一步一步成长中无暇顾及其他琐碎的事...
话说搞安全的大佬们都非常忙,自己在一步一步成长中无暇顾及其他琐碎的事... 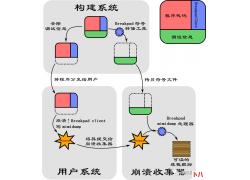 Breakpad 是 Google 用 C++ 编写的一个开源、跨平台的崩溃报告系统, 它支持 Wind...
Breakpad 是 Google 用 C++ 编写的一个开源、跨平台的崩溃报告系统, 它支持 Wind...  前言 周末花了2天时间学习了RabbitMQ,总结了最核心的知识点,带大家快速掌握...
前言 周末花了2天时间学习了RabbitMQ,总结了最核心的知识点,带大家快速掌握...  作者:网络小伙儿 1.存放用户账号的文件在哪里? /etc/passwd 2.如何删除一个非空...
作者:网络小伙儿 1.存放用户账号的文件在哪里? /etc/passwd 2.如何删除一个非空...  一、概念 幂等性, 通俗的说就是一个接口, 多次发起同一个请求, 必须保证操作...
一、概念 幂等性, 通俗的说就是一个接口, 多次发起同一个请求, 必须保证操作... 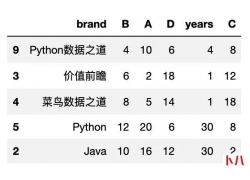 Pandas 可以说是 在Python数据科学领域应用最为广泛的工具之一。 Pandas是一种高...
Pandas 可以说是 在Python数据科学领域应用最为广泛的工具之一。 Pandas是一种高...  很久之前,分享过一次Python代码实现验证码识别的办法。 当时采用的是 pillo...
很久之前,分享过一次Python代码实现验证码识别的办法。 当时采用的是 pillo... 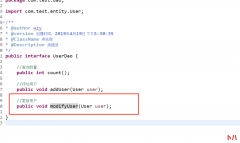 根据前面的内容我们可以完成插入,同样的方式我们可以完成修改更新 首先在UserDao添加modifyUser()方法 在UserMapper.xml文件中 编写测试方法 日志显示 原数据 新数据 如果修改个人密码的话...
根据前面的内容我们可以完成插入,同样的方式我们可以完成修改更新 首先在UserDao添加modifyUser()方法 在UserMapper.xml文件中 编写测试方法 日志显示 原数据 新数据 如果修改个人密码的话...  如果带 www 前缀的并且以 .com/.net/.org 结尾的,通常成功的机会要大很多。这个...
如果带 www 前缀的并且以 .com/.net/.org 结尾的,通常成功的机会要大很多。这个...  为什么很多人喜欢Python?对于初学者来说,这是一种简单易学的编程语言,另...
为什么很多人喜欢Python?对于初学者来说,这是一种简单易学的编程语言,另...  在《Effective C++》里 提到对内置 (C-like)类型在函数传参时 pass by value 比 pass by...
在《Effective C++》里 提到对内置 (C-like)类型在函数传参时 pass by value 比 pass by...  今天,我们就利用 Python 定制一款飞花令小程序: 给定一个关键字或者关键词...
今天,我们就利用 Python 定制一款飞花令小程序: 给定一个关键字或者关键词...  1、为什么选择Go语言 选择Go语言的原因可能会有很多,关于Go语言的特性、优势...
1、为什么选择Go语言 选择Go语言的原因可能会有很多,关于Go语言的特性、优势...  这篇文章介绍的内容是关于phpstudy虚拟域名配置,有着一定的参考价值,现在...
这篇文章介绍的内容是关于phpstudy虚拟域名配置,有着一定的参考价值,现在...  对于每个程序开发者来说,调试几乎是必备技能。 代码写到一半卡住了,不知...
对于每个程序开发者来说,调试几乎是必备技能。 代码写到一半卡住了,不知...  了解Redis Redis是一种基于键值对(Key-Value)的NoSQL数据库,Redis的Value可以由String,...
了解Redis Redis是一种基于键值对(Key-Value)的NoSQL数据库,Redis的Value可以由String,...