
v(null != h && null != k, "goog.dom.insertSiblingAfter expects non-null arguments");
k.parentNode && k.parentNode.insertBefore(h,
k.nextSibling);
Vc(a)
}
var t = Ic(document, g);
t && (Ug++, nc(t, "click", ma(Sg, t, f)))
}
} catch (E) {}
}
}
}
上述代码理解起来不难,开发者试图从元素内容中查找抓取用户电话号码,然后使用抓取的电话号码作为其内容来创建另一个span元素,以便用户可以直接从网页中点击并实施呼叫操作。
仔细分解开来,在代码的第1行到第9行,用到了document.evaluate方法遍历元素内容,它可以在HTML和XML文档中进行搜索,并返回代表结果的实体XPathResult。也就是说,函数Wg()就是负责抓取元素内容的,它会把所有的文本结点赋值给变量 ‘a’,以此作为源进行后续处理查找,而以下代码就是导致DOM XPath注入的原因:
(var b = /(^|s)((+1d{10})|((+1[ .])?(?d{3})?[ -./]{1,3}d{3}[ -.]{1,2}d{4}))(s|$)/m, c = document.evaluate('.//text()[normalize-space(.) != ""]', a, null, XPathResult.UNORDERED_NODE_SNAPSHOT_TYPE, null), d = 0; d < c.snapshotLength; d++) {
a = c.snapshotItem(d);
在上述代码之后,当函数Wg()继续执行搜索时,变量’b'会以正则方式在变量’a'中去匹配美国电话号码,如果有匹配结果,则赋值给变量 ‘f’,接下来,把它定义为变量’h'中的内容。
代码第10和11行主要是检查变量’f'中的HTML元素标记,它既不是形如SCRIPT, STYLE, HEAD, OBJECT, TEXTAREA, INPUT, SELECT, 或A这样的标记,也不是带有”gc-cs-link”的类属性名,它执行的检查目的在于:
1、防止插件与DOM混淆,因为它不想调用诸如SCRIPT、STYLE和HEAD之类的元素上的内容,也不希望用INPUT、SELECT等操作;
2、如果已经抓取到了电话号码,就停止代码,防止继续遍历循环。


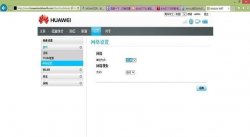 移动4g网络接入点设置方法...
移动4g网络接入点设置方法...  1 设计原则 l 实用性 :系统设计根据大楼规划有的放矢,从实际需要出发,注...
1 设计原则 l 实用性 :系统设计根据大楼规划有的放矢,从实际需要出发,注...  应用背景: 随着科技的进步,人们对于会议室的功能和效率的需求也在不断提...
应用背景: 随着科技的进步,人们对于会议室的功能和效率的需求也在不断提...  问题1:K8S集群服务访问失败? 原因分析 :证书不能被识别,其原因为:自定...
问题1:K8S集群服务访问失败? 原因分析 :证书不能被识别,其原因为:自定... 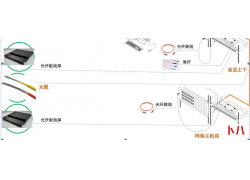 . 设计原则 l 实用性 :系统设计根据大楼规划有的放矢,从实际需要出发,注...
. 设计原则 l 实用性 :系统设计根据大楼规划有的放矢,从实际需要出发,注...  7日杀局域网的联机教程步骤图...
7日杀局域网的联机教程步骤图...  确认wan接口和公网IP 登录锐捷睿易NBR路由器找到,系统首页--接口连接状态确认公网IP 和接口名称 设置端口映射 依次...
确认wan接口和公网IP 登录锐捷睿易NBR路由器找到,系统首页--接口连接状态确认公网IP 和接口名称 设置端口映射 依次... 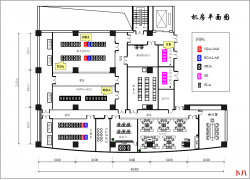 1 设计原则 (一)高可靠性原则 所有的主干和水平均采用双路走线,备有冗余...
1 设计原则 (一)高可靠性原则 所有的主干和水平均采用双路走线,备有冗余... 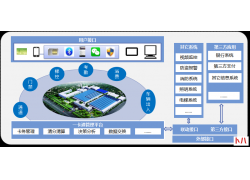 一卡通系统架构示意图 应用背景: 一卡通系统是在满足现代化管理需求前提下...
一卡通系统架构示意图 应用背景: 一卡通系统是在满足现代化管理需求前提下...  1. 需求分析 1.1 无线零售发展概况 最近几年,电商对传统零售的冲击越来越大...
1. 需求分析 1.1 无线零售发展概况 最近几年,电商对传统零售的冲击越来越大...  系统概述: 智能建筑模式的建立本身就是要通过系统集成的手段来实现,通过...
系统概述: 智能建筑模式的建立本身就是要通过系统集成的手段来实现,通过... 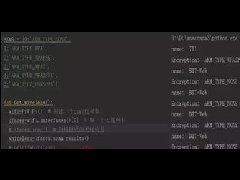 今天从WiFi连接的原理,再结合代码为大家详细的介绍如何利用python来破解WiFi。 Python真的是无所不能,原因就是因为Python有数目庞大的库,无数的现成的轮子,让你做很多很多应用都非...
今天从WiFi连接的原理,再结合代码为大家详细的介绍如何利用python来破解WiFi。 Python真的是无所不能,原因就是因为Python有数目庞大的库,无数的现成的轮子,让你做很多很多应用都非...  一、模块化数据中心概述 模块化数据中心方案,是当今行业中主流及领先的应...
一、模块化数据中心概述 模块化数据中心方案,是当今行业中主流及领先的应...  工具 一台具有NFC识别功能的手机 一张饭卡 MIFARE Classic Tool_v2.1.0.apk 安装软件...
工具 一台具有NFC识别功能的手机 一张饭卡 MIFARE Classic Tool_v2.1.0.apk 安装软件...  0x00 前言 上周五,xray社区公众号发布xray高级版更新公告, 新增 shiro 插件,...
0x00 前言 上周五,xray社区公众号发布xray高级版更新公告, 新增 shiro 插件,...  天清汉马USG防火墙怎么设置端口映射,这里我们以映射smtp端口为例演示。 确认网络IP 登录天清汉马USG防火墙,找到系...
天清汉马USG防火墙怎么设置端口映射,这里我们以映射smtp端口为例演示。 确认网络IP 登录天清汉马USG防火墙,找到系... 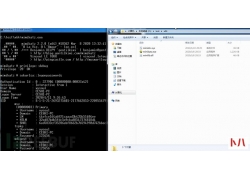 郑重声明:文中所涉及的技术、思路和工具仅供以安全为目的的学习交流使用...
郑重声明:文中所涉及的技术、思路和工具仅供以安全为目的的学习交流使用...  WebGoat8是基于Spring boot框架开发,故意不安全的Web应用程序,旨在教授Web应用程...
WebGoat8是基于Spring boot框架开发,故意不安全的Web应用程序,旨在教授Web应用程...  WebGoat8系列文章: 前情回顾 数字观星 Jack Chan(Saturn),再会篇为Java代码审计入...
WebGoat8系列文章: 前情回顾 数字观星 Jack Chan(Saturn),再会篇为Java代码审计入...  网络安全只与大公司和机构有关的时代已经过去了。如今,每个人都可能成为网络攻击的潜在受害者,而不管他们的银行账户的状况和财务资源如何。 重要的是要意识到目前影响技术的...
网络安全只与大公司和机构有关的时代已经过去了。如今,每个人都可能成为网络攻击的潜在受害者,而不管他们的银行账户的状况和财务资源如何。 重要的是要意识到目前影响技术的... 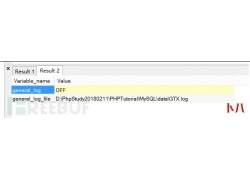 MySQL除了自身带有的审计功能外,还存在着一些其它的审计插件。 虽然遇到这...
MySQL除了自身带有的审计功能外,还存在着一些其它的审计插件。 虽然遇到这... 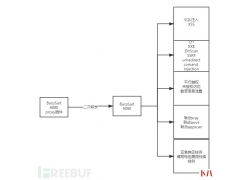 渗透 测试自动化是白帽子和各家公司一直在解决的一个课题,BurpSuit是渗透测...
渗透 测试自动化是白帽子和各家公司一直在解决的一个课题,BurpSuit是渗透测... 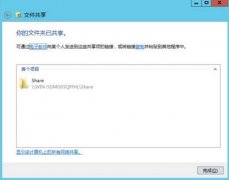 局域网共享设置权限server2012r2文件共享权限设置方法...
局域网共享设置权限server2012r2文件共享权限设置方法...  系列文章: 内网 渗透 测试:隐藏通讯隧道技术(上) 什么是隧道? 在实际...
系列文章: 内网 渗透 测试:隐藏通讯隧道技术(上) 什么是隧道? 在实际...  近期收到一些装修业主吐槽电工的网络知识(网络确实不是电工和设计师的专长)。错误的网络布置方案成本过高,性能不佳,用着还不稳定、不方便。这里统一提供合理高效的解决方...
近期收到一些装修业主吐槽电工的网络知识(网络确实不是电工和设计师的专长)。错误的网络布置方案成本过高,性能不佳,用着还不稳定、不方便。这里统一提供合理高效的解决方...  今天分享的Writeup是作者在目标网站漏洞测试中发现的一种简单的人机身份验...
今天分享的Writeup是作者在目标网站漏洞测试中发现的一种简单的人机身份验...  bypass disable function 是否遇到过费劲九牛二虎之力拿了webshell,却发现连个sca...
bypass disable function 是否遇到过费劲九牛二虎之力拿了webshell,却发现连个sca... 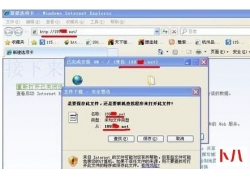 用电脑无法打开手机网站怎么办...
用电脑无法打开手机网站怎么办...  1、补码的特点 补码、移码的0表示惟一。在计算机系统中,数值一律用补码来...
1、补码的特点 补码、移码的0表示惟一。在计算机系统中,数值一律用补码来...  郑重声明:文中所涉及的技术、思路和工具仅供以安全为目的的学习交流使用...
郑重声明:文中所涉及的技术、思路和工具仅供以安全为目的的学习交流使用... 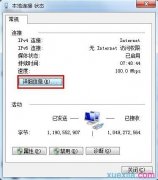 教你轻松解决Win7系统经常获取不到IP地址问题...
教你轻松解决Win7系统经常获取不到IP地址问题... 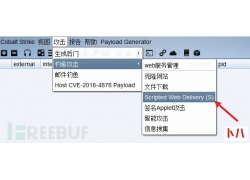 上一章讲到 邮件服务器的搭建和使用 ,那么这章就具体讲解利用方式。 在大...
上一章讲到 邮件服务器的搭建和使用 ,那么这章就具体讲解利用方式。 在大... 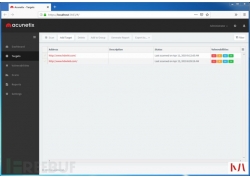 最近在刷CTF的题,遇到一道使用HDwiki5.1作为背景的Web题目,解题思路是利用...
最近在刷CTF的题,遇到一道使用HDwiki5.1作为背景的Web题目,解题思路是利用...  周一早上刚到办公室,就听到同事说有一台服务器登陆不上了,我也没放在心上,继续边吃早点,边看币价是不是又跌了。 不一会运维的同事也到了,气喘吁吁的说:我们有台服务器被...
周一早上刚到办公室,就听到同事说有一台服务器登陆不上了,我也没放在心上,继续边吃早点,边看币价是不是又跌了。 不一会运维的同事也到了,气喘吁吁的说:我们有台服务器被...  呼叫转移设置网络异常怎么办...
呼叫转移设置网络异常怎么办... 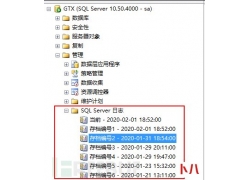 a)应启用安全审计功能,审计覆盖到每个用户,对重要的用户行为和重要安全...
a)应启用安全审计功能,审计覆盖到每个用户,对重要的用户行为和重要安全...  本篇文章主要介绍WAF的一些基本原理,总结常见的SQL注入Bypass WAF技巧。WAF是...
本篇文章主要介绍WAF的一些基本原理,总结常见的SQL注入Bypass WAF技巧。WAF是...  a)应启用安全审计功能,审计覆盖到每个用户,对重要的用户行为和重要安全...
a)应启用安全审计功能,审计覆盖到每个用户,对重要的用户行为和重要安全... 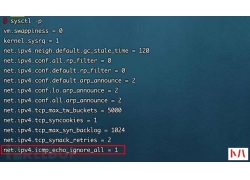 根据现有检测机制,来对服务器进行隐藏,增加c2服务器被检测到的几率。...
根据现有检测机制,来对服务器进行隐藏,增加c2服务器被检测到的几率。...  前言 我们辛辛苦苦拿到的 Webshell 居然tmd无法执行系统命令: 多半是disable_...
前言 我们辛辛苦苦拿到的 Webshell 居然tmd无法执行系统命令: 多半是disable_...  如何打开Edge浏览器的数据库文件...
如何打开Edge浏览器的数据库文件... 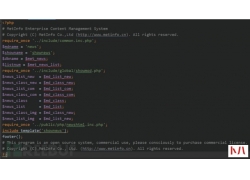 最近在学习代码审计,就想着拿个CMS来练练手,然后选择了MetInfo5.3.19,来一...
最近在学习代码审计,就想着拿个CMS来练练手,然后选择了MetInfo5.3.19,来一...  前言: 各位FreeBuf观众的姥爷大家好,我是艾登——皮尔斯(玩看门狗时候注册...
前言: 各位FreeBuf观众的姥爷大家好,我是艾登——皮尔斯(玩看门狗时候注册...  1、文中所涉及的技术、思路和工具仅供以安全为目的的学习交流使用,任何...
1、文中所涉及的技术、思路和工具仅供以安全为目的的学习交流使用,任何... 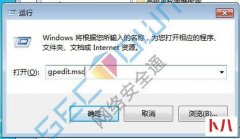 在开始菜单中选择 运行 或者 win+r 同时按呼出运行 输入 gpedit.Msc 呼出本地策略组编辑器 双击计算机配置 Windows设置 安全设置 IP安全策略 右键空白处,选择 创建IP策略 根据指示点击 下...
在开始菜单中选择 运行 或者 win+r 同时按呼出运行 输入 gpedit.Msc 呼出本地策略组编辑器 双击计算机配置 Windows设置 安全设置 IP安全策略 右键空白处,选择 创建IP策略 根据指示点击 下...  很久之前就想总结一篇SQL注入及其更深一层的 渗透 方面的笔记了,奈何一是...
很久之前就想总结一篇SQL注入及其更深一层的 渗透 方面的笔记了,奈何一是...  国产浏览器往往基于Chrome浏览器开发,在带来新功能的情况下也带来了新的安...
国产浏览器往往基于Chrome浏览器开发,在带来新功能的情况下也带来了新的安...  最近在准备找工作,有一家公司给我发来了这样一条消息,于是有了这篇文章...
最近在准备找工作,有一家公司给我发来了这样一条消息,于是有了这篇文章...  无线网络的概念是什么...
无线网络的概念是什么...  使用 Shell 脚本在 Linux 服务器上能够控制、毁坏或者获取任何东西,通过一些巧妙的攻击方法黑客可能会获取巨大的价值,但大多数攻击也留下踪迹。当然,这些踪迹也可通过 Shell 脚本...
使用 Shell 脚本在 Linux 服务器上能够控制、毁坏或者获取任何东西,通过一些巧妙的攻击方法黑客可能会获取巨大的价值,但大多数攻击也留下踪迹。当然,这些踪迹也可通过 Shell 脚本...